learning rate 调整方案
在深度学习中,学习率调整是一种重要的技术,用于优化模型的训练过程。学习率是控制模型参数更新幅度的超参数,它决定了在每次参数更新中应用的梯度下降的步长。合适的学习率调整策略可以帮助模型更快地收敛或避免陷入局部最优点。
学习率调度(Learning Rate Scheduling):学习率调度是根据训练的迭代次数或验证误差的变化动态地调整学习率。
2 pytorch中 torch.optim.lr_scheduler 使用方法
torch.optim.lr_scheduler 提供了几种根据训练轮数来调整学习率的方法。
torch.optim.lr_scheduler.ReduceLROnPlateau 允许根据一些验证指标动态减小学习率。
2.1 使用方法
学习率调度应该在优化器更新之后应用;例如,你应该按照以下方式编写代码:
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()大多数学习率调度器可以连续调用(也称为链接调度器)。结果是,每个调度器都会按顺序应用在前一个调度器得到的学习率上。
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler1.step()
scheduler2.step()scheduler 更新的模板为:
scheduler = ...
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3 学习率调度器 策略全解 (learning-rate scheduler)
3.1 lr_scheduler.LambdaLR
原理:
将每个参数组的学习率设置为初始学习率乘以给定函数。当last_epoch=-1时,将初始学习率设置为lr。伪代码展示:
# Assuming optimizer has two groups.
lambda1 = lambda epoch: epoch // 30
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()思考:为什么要用 last_epoch 呢???
3.2 lr_scheduler.MultiplicativeLR
原理:
将每个参数组的学习率乘以指定函数中给定的因子。当last_epoch=-1时,将初始学习率设置为lr。pytorch 实现:
lmbda = lambda epoch: 0.95
scheduler = MultiplicativeLR(optimizer, lr_lambda=lmbda)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3.3 lr_scheduler.StepLR
原理:
每经过 step_size 个周期,将每个参数组的学习率按 gamma 进行衰减。请注意,此衰减可以与来自调度器外部的学习率的其他变化同时发生。当 last_epoch=-1 时,将初始学习率设置为 lr。图示:
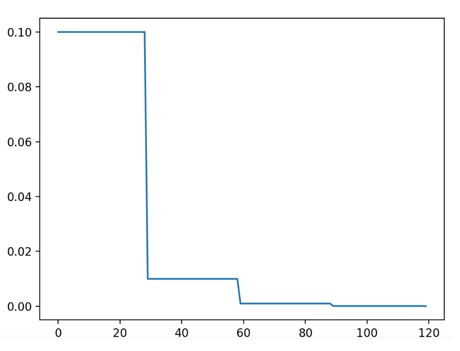
伪代码展示:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
# ...
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3.4 lr_scheduler.MultiStepLR
原理:
一旦训练周期数达到里程碑(milestones)之一,就会按 gamma 对每个参数组的学习率进行衰减。请注意,此衰减可以与来自调度器外部的学习率的其他变化同时发生。当 last_epoch=-1 时,将初始学习率设置为 lr。图示:
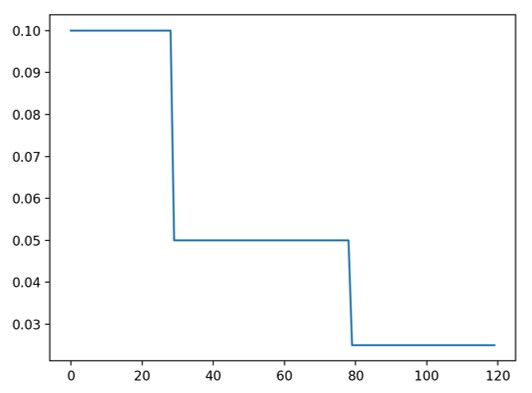
伪代码展示:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3.5 lr_scheduler.ConstantLR
原理:
将每个参数组的学习率按一个小的常数因子进行衰减,直到训练周期数达到预定义的里程碑(total_iters)。请注意,此衰减可以与来自调度器外部的学习率的其他变化同时发生。当 last_epoch=-1 时,将初始学习率设置为 lr。伪代码展示:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.025 if epoch == 0
# lr = 0.025 if epoch == 1
# lr = 0.025 if epoch == 2
# lr = 0.025 if epoch == 3
# lr = 0.05 if epoch >= 4
scheduler = ConstantLR(self.opt, factor=0.5, total_iters=4)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3.6 lr_scheduler.LinearLR
原理:
将每个参数组的学习率通过线性变化的小乘法因子进行衰减,直到训练周期数达到预定义的里程碑(total_iters)。请注意,此衰减可以与来自调度器外部的学习率的其他变化同时发生。当 last_epoch=-1 时,将初始学习率设置为 lr。图示:
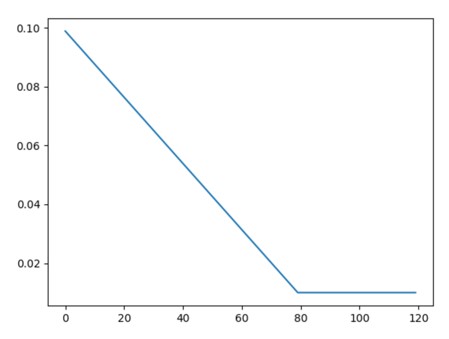
伪代码展示:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.025 if epoch == 0
# lr = 0.03125 if epoch == 1
# lr = 0.0375 if epoch == 2
# lr = 0.04375 if epoch == 3
# lr = 0.05 if epoch >= 4
scheduler = LinearLR(self.opt, start_factor=0.5, total_iters=4)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3.7 lr_scheduler.ExponentialLR
原理:
每个训练周期,将每个参数组的学习率按 gamma 进行衰减。当 last_epoch=-1 时,将初始学习率设置为 lr。图示:
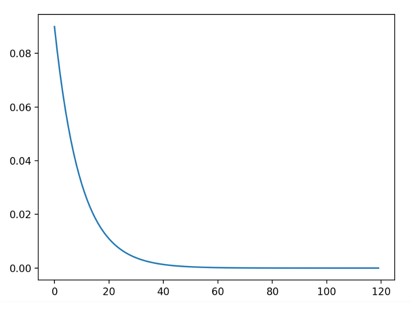
伪代码展示:
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import ExponentialLR
# 定义模型和优化器
model = YourModel()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 定义学习率调度器
scheduler = ExponentialLR(optimizer, gamma=0.9)
# 训练循环
for epoch in range(num_epochs):
# 在每个训练周期之前更新学习率
scheduler.step()
# 执行训练和参数更新
train(model, optimizer)
# 打印当前学习率: 每个周期都会减小为上一个周期的 gamma 倍。
print("Epoch:", epoch, "Learning Rate:", scheduler.get_lr())3.8 lr_scheduler.PolynomialLR
原理:
使用多项式函数来在给定的 total_iters 中衰减每个参数组的学习率。当 last_epoch=-1 时,将初始学习率设置为 lr。
- 伪代码展示:
# Assuming optimizer uses lr = 0.001 for all groups
# lr = 0.001 if epoch == 0
# lr = 0.00075 if epoch == 1
# lr = 0.00050 if epoch == 2
# lr = 0.00025 if epoch == 3
# lr = 0.0 if epoch >= 4
scheduler = PolynomialLR(self.opt, total_iters=4, power=1.0)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3.9 lr_scheduler.CyclicLR
原理:
根据循环学习率策略(CLR),设置每个参数组的学习率。该策略在两个边界之间以恒定的频率循环调整学习率,两个边界之间的距离可以按每次迭代或每个循环来进行缩放。循环学习率策略在每个批次之后改变学习率。在使用批次进行训练后,应调用 step 方法。图示:
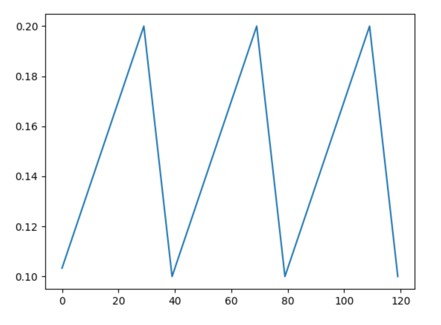
该类中有三种内置的策略,如论文中所述:
“triangular”:基本的三角循环,无振幅缩放。
“triangular2”:基本的三角循环,每个循环将初始振幅缩小一半。
“exp_range”:每个循环迭代时,将初始振幅按 进行缩放。
伪代码展示:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.01, max_lr=0.1)
data_loader = torch.utils.data.DataLoader(...)
for epoch in range(10):
for batch in data_loader:
train_batch(...)
scheduler.step()3.10 lr_scheduler.OneCycleLR
论文链接: Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates
原理:
根据 one cycle学习率策略设置每个参数组的学习率。one cycle策略将学习率从初始学习率逐渐退火到最大学习率,然后再从最大学习率退火到远低于初始学习率的最小学习率。one cycle学习率策略在每个批次之后改变学习率。在使用批次进行训练后,应调用 step 方法。图示:
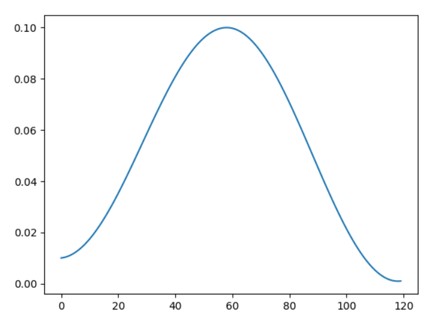
注释:退火是一种通过加热和冷却金属来改变其晶体结构,从而改变其性质和硬度的过程。类比到学习率调整中,"退火"的概念表示在训练过程中通过逐渐减小学习率来改变模型的行为和性能。这种减小学习率的过程类似于金属冶炼中的加热和冷却过程,通过逐步调整学习率来"冷却"模型,使其逐渐稳定并达到更好的性能状态。
注意:此调度器不可链式使用。
请注意,循环中的总步数可以通过以下两种方式之一进行确定(按优先顺序列出):
- 明确提供 total_steps 的值。
- 提供 epochs(训练周期数)和 steps_per_epoch(每个训练周期的步数)。在这种情况下,总步数可以通过 total_steps = epochs * steps_per_epoch 推断出来。
此调度器的默认行为遵循 fastai 对one cycle的实现,其声称“未发表的研究结果显示,仅使用两个阶段可以获得更好的结果”。如果想模仿原论文的行为,请将 three_phase 设置为 True。
- 伪代码展示:
data_loader = torch.utils.data.DataLoader(...)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, steps_per_epoch=len(data_loader), epochs=10)
for epoch in range(10):
for batch in data_loader:
train_batch(...)
optimizer.step()
scheduler.step()3.11 lr_scheduler.CosineAnnealingLR
注意:
由于该调度器是递归定义的,学习率可以同时被其他操作器在此调度器之外修改.图示:
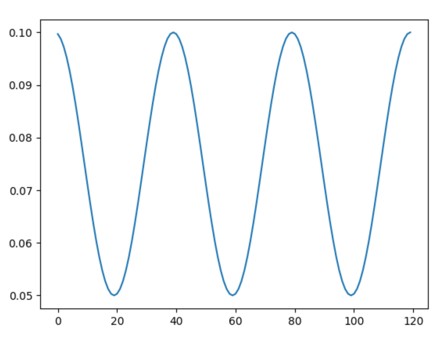
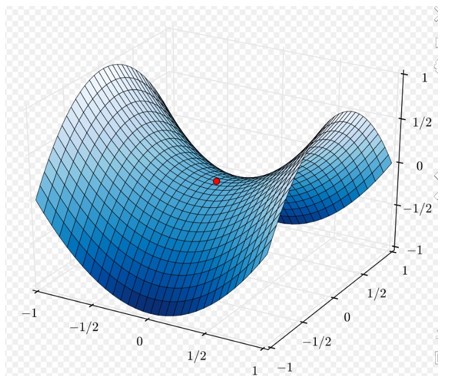
可有效解决鞍点问题:
伪代码展示:
import torch
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
# 定义参数
total_epochs = 100 # 总的训练周期数
initial_lr = 0.1 # 初始学习率
min_lr = 0.001 # 最小学习率
# 创建优化器和学习率调度器
optimizer = optim.SGD(model.parameters(), lr=initial_lr)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=total_epochs, eta_min=min_lr)
# 在每个周期内进行训练
for epoch in range(total_epochs):
# 执行训练步骤
# 更新学习率
scheduler.step()
# 获取当前学习率
current_lr = optimizer.param_groups[0]['lr']
print(f"Epoch {epoch+1}/{total_epochs}, Learning Rate: {current_lr}")3.12 lr_scheduler.CosineAnnealingWarmRestarts
原理:
带 Warm Restarts 的余弦退火学习率。图示:
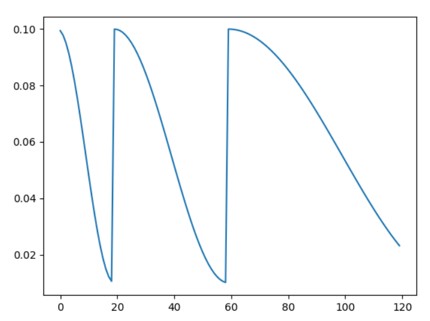
- 公式:
- 伪代码展示:
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0, T_mult)
iters = len(dataloader)
for epoch in range(20):
for i, sample in enumerate(dataloader):
inputs, labels = sample['inputs'], sample['labels']
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step(epoch + i / iters)可直接设定中间过程:
- 伪代码展示:
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0, T_mult)
for epoch in range(20):
scheduler.step()
scheduler.step(26)
scheduler.step() # scheduler.step(27), instead of scheduler(20)3.13 ReduceLROnPlateau
原理:
当度量指标停止改善时,减小学习率。一旦学习停滞不前,通过将学习率减小2-10倍,模型通常会受益。该调度器会监测一个度量指标的数值,如果在连续'patience'个训练周期中没有改善,则会降低学习率。伪代码展示:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in range(10):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)3.14 lr_scheduler.ChainedScheduler
原理:
将学习率调度器的列表链接在一起。它接受一个可链接的学习率调度器列表,并通过一次调用执行它们各自的连续step()函数。伪代码展示:
# Assuming optimizer uses lr = 1. for all groups
# lr = 0.09 if epoch == 0
# lr = 0.081 if epoch == 1
# lr = 0.729 if epoch == 2
# lr = 0.6561 if epoch == 3
# lr = 0.59049 if epoch >= 4
scheduler1 = ConstantLR(self.opt, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(self.opt, gamma=0.9)
scheduler = ChainedScheduler([scheduler1, scheduler2])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()3.15 lr_scheduler.SequentialLR
原理:
接收一个调度器列表,这些调度器在优化过程中按顺序调用,并接收里程碑点列表,以提供确切的间隔来反映在给定历元应该调用哪个调度器。伪代码展示:
# Assuming optimizer uses lr = 1. for all groups
# lr = 0.1 if epoch == 0
# lr = 0.1 if epoch == 1
# lr = 0.9 if epoch == 2
# lr = 0.81 if epoch == 3
# lr = 0.729 if epoch == 4
scheduler1 = ConstantLR(self.opt, factor=0.1, total_iters=2)
scheduler2 = ExponentialLR(self.opt, gamma=0.9)
scheduler = SequentialLR(self.opt, schedulers=[scheduler1, scheduler2], milestones=[2])
for epoch in range(100):
train(...)
validate(...)
scheduler.step()4 探索源码
- lr-shecuder 类有哪些常用的方法;
- 从pytorch 代码仓中找到这些方法;
- 并理解其含义.