1. AMP 论文
2. Apex
- Pytorch 的 AMP 其实是从 apex 简化而来的,和 apex 的 O1 相当。
apex 几个级别
- O0: FP32 training
Your incoming model should be FP32 already, so this is likely a no-op. O0 can be useful to establish an accuracy baseline.
c++
Default properties set by O0:
cast_model_type=torch.float32
patch_torch_functions=False
keep_batchnorm_fp32=None (effectively, "not applicable," everything is FP32)
master_weights=False
loss_scale=1.0- O1: Mixed Precision (recommended for typical use)
Patch all Torch functions and Tensor methods to cast their inputs according to a whitelist-blacklist model. Whitelist ops (for example, Tensor Core-friendly ops like GEMMs and convolutions) are performed in FP16. Blacklist ops that benefit from FP32 precision (for example, softmax) are performed in FP32. O1 also uses dynamic loss scaling, unless overridden.
c++
Default properties set by O1:
cast_model_type=None (not applicable)
patch_torch_functions=True
keep_batchnorm_fp32=None (again, not applicable, all model weights remain FP32)
master_weights=None (not applicable, model weights remain FP32)
loss_scale="dynamic"- O2: "Almost FP16" Mixed Precision
O2 casts the model weights to FP16, patches the model's forward method to cast input data to FP16, keeps batchnorms in FP32, maintains FP32 master weights, updates the optimizer's param_groups so that the optimizer.step() acts directly on the FP32 weights (followed by FP32 master weight->FP16 model weight copies if necessary), and implements dynamic loss scaling (unless overridden). Unlike O1, O2 does not patch Torch functions or Tensor methods.
c++
Default properties set by O2:
cast_model_type=torch.float16
patch_torch_functions=False
keep_batchnorm_fp32=True
master_weights=True
loss_scale="dynamic"- O3: FP16 training
O3 may not achieve the stability of the true mixed precision options O1 and O2. However, it can be useful to establish a speed baseline for your model, against which the performance of O1 and O2 can be compared. If your model uses batch normalization, to establish "speed of light" you can try O3 with the additional property override keep_batchnorm_fp32=True (which enables cudnn batchnorm, as stated earlier).
c++
Default properties set by O3:
cast_model_type=torch.float16
patch_torch_functions=False
keep_batchnorm_fp32=False
master_weights=False
loss_scale=1.03. pytorch 中amp的用法
python
import torch
from torch.cuda.amp import autocast as autocast
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast(device_type='cuda', dtype=torch.float16):
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()4 fp16 训练的优势和不足
4.1 使用FP16训练神经网络,相对比使用FP32带来的优点
- 减少内存占用:FP16的位宽是FP32的一半,因此权重等参数所占用的内存也是原来的一半,节省下来的内存可以放更大的网络模型或者使用更多的数据进行训练。
- 加快通讯效率:针对分布式训练,特别是在大模型训练的过程中,通讯的开销制约了网络模型训练的整体性能,通讯的位宽少了意味着可以提升通讯性能,减少等待时间,加快数据的流通。
- 计算效率更高:在特殊的AI加速芯片如华为Ascend 910和310系列,或者NVIDIA VOTAL架构的Titan V and Tesla V100的GPU上,使用FP16的执行运算性能比FP32更加快。
4.2 FP16训练的问题
但是使用FP16同样会带来一些问题,其中最重要的是1)精度溢出和2)舍入误差。
- 数据溢出:数据溢出比较好理解,FP16的有效数据表示范围为 6.10×10−5∼65504 ,FP32的有效数据表示范围为 1.4×10−45 1.7×1038 。可见FP16相比FP32的有效范围要窄很多,使用FP16替换FP32会出现上溢(Overflow)和下溢(Underflow)的情况。而在深度学习中,需要计算网络模型中权重的梯度(一阶导数),因此梯度会比权重值更加小,往往容易出现下溢情况。
- 舍入误差:Rounding Error指示是当网络模型的反向梯度很小,一般FP32能够表示,但是转换到FP16会小于当前区间内的最小间隔,会导致数据溢出。如0.00006666666在FP32中能正常表示,转换到FP16后会表示成为0.000067,不满足FP16最小间隔的数会强制舍入。
5. loss 进行 scale 缩放
5.1 损失缩放基本原理
损失放大是需要结合混合精度实现的,其主要的主要思路是:
- Scale up阶段,网络模型前向计算后在反响传播前,将得到的损失变化值DLoss增大2^K倍。
- Scale down阶段,反向传播后,将权重梯度缩2^K倍,恢复FP32值进行存储。
5.2 动态损失缩放(Dynamic Loss Scaling):
上面提到的损失缩放都是使用一个默认值对损失值进行缩放,为了充分利用FP16的动态范围,可以更好地缓解舍入误差,尽量使用比较大的放大倍数。总结动态损失缩放算法,就是每当梯度溢出时候减少损失缩放规模,并且间歇性地尝试增加损失规模,从而实现在不引起溢出的情况下使用最高损失缩放因子,更好地恢复精度。
5.3 动态损失缩放的算法
- 动态损失缩放的算法会从比较高的缩放因子开始(如2^24),然后开始进行训练迭代中检查数是否会溢出(Infs/Nans);
- 如果没有梯度溢出,则不进行缩放,继续进行迭代;如果检测到梯度溢出,则缩放因子会减半,重新确认梯度更新情况,直到数不产生溢出的范围内;
- 在训练的后期,loss已经趋近收敛稳定,梯度更新的幅度往往小了,这个时候可以允许更高的损失缩放因子来再次防止数据下溢。
- 因此,动态损失缩放算法会尝试在每N(N=2000)次迭代将损失缩放增加F倍数,然后执行步骤2检查是否溢出。
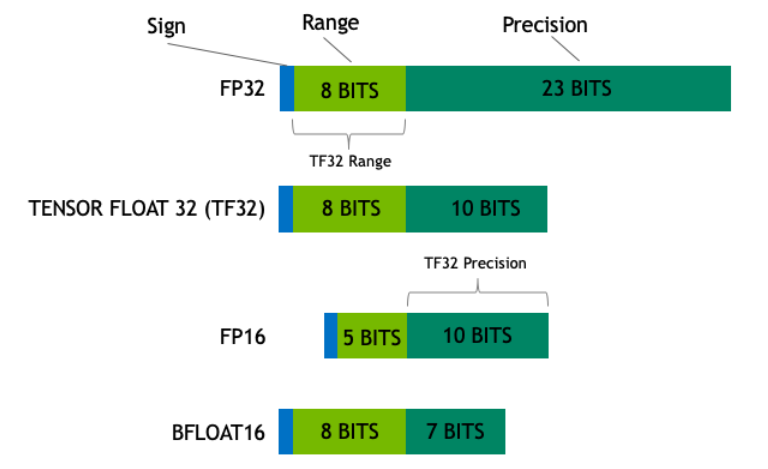
6 使用bf16 数据类型
float16 的情况:
float16 的动态范围较小,容易导致梯度下溢或上溢。
使用 float16 时,通常需要通过 scaler(如 GradScaler)对损失进行缩放,以保持梯度的数值稳定性。
bfloat16 的情况:
bfloat16 的动态范围与 float32 相近,数值稳定性较好。
使用 bfloat16 时,通常不需要额外的 scaler 进行缩放。
import torch
import torch.nn as nn
import torch.optim as optim
# 模型和优化器
model = nn.Linear(10, 1).to('cuda')
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 使用 bfloat16
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
output = model(torch.randn(16, 10).to('cuda'))
loss = nn.MSELoss()(output, torch.randn(16, 1).to('cuda'))
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()