从 GPT1 到 GPT4

1 GPT1
1.1 自回归模型
Google 的 Transformer(Attention is All You Need) 于 2017 年 6 月发表,一年后,OpenAI 的团队发表了 GPT ,又过了两个月,Google 的另一个团队发表了 BERT。
缩写 GPT 来自论文题目的 Generative Pre-Training,生成式预训练,维基百科2中的表述是 Generative Pre-trained Transformer,二者指代一致。这是一个通用概念,当前常见的具有聊天功能的 AI 或者说 LLM 其实都可以称作 GPT。
GPT 是一种自回归(Auto-Regressive,AR)模型,在进一步了解 GPT 之前,我们重识自回归和非自回归:

自回归(Auto-Regressive)
自回归生成是指序列生成过程中,每个新生成的 token 依赖于之前生成的 token。这意味着生成过程是串行的,每一步的输入由前面已生成的 token 组成的上下文序列构成。例如:
假设要生成一个长度为 的句子 y = (y_1, y_2, \dots, y_T),在生成句子的过程中,
- 首先生成 ,
- 然后在生成 时需要考虑 ;
- 在生成 时,需要考虑 ,
以此类推,直到生成结束符号 "<end>"。
这种设计确保了生成过程中的连贯性和逻辑一致性。
非自回归(Non-Autoregressive) 非自回归生成是一种并行生成的方式,一次性生成多个甚至全部的 token,从而显著提高生成速度,但也会牺牲一定的生成质量。
EXTENSION: 现在也有工作使用非自回归模型作为“预言家”来指导自回归模型并行生成,从而在生成质量不变的情况下大幅度提高生成速度,以“空间”换时间。例如:

1.2 GPT1 贡献
预训练 + 微调」范式的验证(基于 Transformer 解码器)
- 采用了仅由 Transformer decoder 堆叠的架构(使用 Masked self-attention 从左到右预测下一个词),在大规模未标注语料上进行生成式预训练。
- 随后,模型在下游任务(文本蕴含、文本分类、问答等)上通过有监督微调来适配不同场景,最终在 9/12 的任务上取得了 SOTA,证明了 Transformer 架构在语言建模上的
可行性。 - 虽然在 GPT 出现之前已有基于预训练词向量(Word2Vec [MCCD13]、GloVe [PSM14])或 ELMo 等双向语言模型的类似思路,但 GPT-1
首次在一个大规模、纯 Transformer 解码器上系统性地验证了「预训练 + 微调」范式的有效性,为后续基于 Transformer 架构的预训练语言模型(如 BERT、T5)奠定了基础。
引入统一的任务输入格式
- 通过
在输入文本中添加特殊标记以及拼接文本,将不同下游任务(文本蕴含、问答、情感分析等)的结构化输入统一转换为连续序列的形式。 - 这种方法
减少了为不同任务单独设计模型结构的需求,仅通过调整输入格式即可适应不同任务,使得同一个预训练语言模型可以在不同任务之间复用。
- 通过
1.3 GPT1 模型架构
Transformer 是 GPT 的“巨人肩膀”,而 GPT 对于 BERT 也是如此。在阅读过 BERT 的论文后,可以感受到许多思想与 GPT 完全同频:
- 预训练与微调范式的使用
- Transformer 架构的使用
- GPT 使用 Transformer 解码器(decoder-only)。
- BERT 使用 Transformer 编码器(encoder-only)。

decoder 模型结构

让我们自顶向下的理解这个架构,下文所说的词/词元实际上就是 Token。
- 顶部:Text Prediction 和 Task Classifier
- Text Prediction:用于生成任务,预测下一个词。
- Task Classifier:用于分类任务,如情感分析或文本蕴含任务。
- 中部:Transformer 架构
遵循原论文的表达将其称之为 transformer_block,其中每一层包含:
Layer Norm (LN) + 残差连接 (+) 对应于 Transformer 架构中的 Add & Norm。
Masked Multi-Head Self-Attention: 掩码多头自注意力机制,在生成任务中,每次预测一个词时,当前词只能看到左侧的上下文信息,未来的词和预测的词都会被掩盖。
对应于 Transformer 架构中 Masked Multi-Head Attention。
前馈网络 (Feed-Forward Network, FFN)
左侧的 12x 表示堆叠了12层 transformer_block。
- 底部:Text & Position Embed
- Text Embed:将输入的词转化为可训练的嵌入向量。
- Position Embed:使用可学习的位置信息嵌入,这里和 Transformer 默认的正余弦位置编码不同,但 Transformer 论文的 Table 3 (E) 中有对比二者的性能差异,所以并非一个新的方法。
从架构上看,Decoder 相较于 Encoder 多了掩码机制和交叉注意力,实际上真正区分二者的是自注意力中的掩码机制,防止模型在生成时看到未来的词。GPT 的架构可以被视为去除了交叉注意力的 Decoder。
1.4 GPT1 VS BERT
在《BERT 论文精读》中有说到:“BERT 是第一个使用预训练与微调范式,在一系列 NLP 任务(包括句子层面和词元层面)都达到 SOTA 的模型。”这句话的关键在于“都”字,因为实际上,GPT 更早地使用了预训练与微调的范式,只不过当时并没有在 12 个任务上全都达到最佳,而是在 9 个任务上超越了当时的 SOTA。
Transformer 是 GPT 的“巨人肩膀”,而 GPT 对于 BERT 也是如此。在阅读过 BERT 的论文后,可以感受到许多思想与 GPT 完全同频:
- 预训练与微调范式的使用
- Transformer 架构的使用
- GPT 使用 Transformer 解码器(decoder-only)。
- BERT 使用 Transformer 编码器(encoder-only)。
1.5 处理不同任务

GPT 将不同的自然语言处理(NLP)任务统一为序列格式
GPT 将不同的自然语言处理(NLP)任务的输入转化为统一的序列格式,使得预训练的生成模型(图中的 Transformer)可以直接接受它们进行处理,避免为每个任务设计特定的模型架构。以下符号将遵循原论文的表述,这里将用到三种特殊词元(Special Token):
- 开始词元(Start Token): ⟨s⟩,表示序列起始。
- 结束词元(End Token): ⟨e⟩,表示序列结束。
- 分隔词元(Delimiter Token): $,用于分隔子序列,例如前提句和假设句,问题和答案。
这种统一的序列格式使得 GPT 能够灵活地处理各种 NLP 任务,而无需为每个任务单独设计模型架构。
这些标记并不是为人类设计的,而是为模型提供明确的语义提示,以便在训练中建立序列关系。注意,这些符号在预训练时是不存在的,微调赋予了它们意义。
- 文本分类(Classification) 文本分类任务的输入是单一文本,目标是根据文本内容预测类别(例如电影评论情感分析:积极或消极)。
输入格式:
⟨ s ⟩ 文本 ⟨ e ⟩- 文本蕴含(Textual Entailment) 文本蕴含任务,也称自然语言推理(NLI)4,目标是判断前提(Premise)与假设(Hypothesis)之间的关系:
- 蕴含(Entailment):由前提可以推出假设,p ⇒ \Rightarrow⇒ h。
- 矛盾(Contradiction):前提与假设相矛盾。
- 无关(Neutral):前提和假设无直接关联。
这是一个三分类问题,举个例子:
蕴含(positive TE,premise entails hypothesis):
前提:“所有鸟类都有翅膀。” 假设:“麻雀有翅膀。” 关系:假设可以从前提推导出,因此为蕴含。 矛盾(negative TE,premise contradicts hypothesis):
前提:“所有鸟类都有翅膀。” 假设:“企鹅没有翅膀。” 关系:假设与前提的事实相矛盾,因此为矛盾(对了,企鹅是鸟)。 无关(non-TE,premise does not entail nor contradict):
前提:“所有鸟类都有翅膀。” 假设:“所有鸟类都会飞。” 关系:假设无法从前提中推导,也不矛盾,因此为无关。
输入格式:
⟨ s ⟩ 前提 $ 假设 ⟨ e ⟩
- 语义相似性(Semantic Similarity) 在语义相似性任务中,目标是判断两个句子是否在语义上相似,例如 Quora 问题对检测(Quora Question Pairs,QQP)要求识别两个问题是否相似。
“Similarity For similarity tasks, there is no inherent ordering of the two sentences \
being compared. To reflect this, we modify the input sequence to contain both \ possible sentence orderings (with a delimiter in between) and process each independently to produce two sequence representations h^m_{l}
which are added element-wise before being fed into the linear output layer.”处理句子对以判断语义相似性
将句子对按照两种可能的顺序输入模型(即
A;B和B;A)。对两种输入序列分别处理,生成的最后一层激活向量 $ h^m_l $ 进行逐元素相加(element-wise addition)。
加和后的表示被输入到线性层中,用于判断语义相似性。
⟨s⟩ 句子A $ 句子B ⟨e⟩
⟨s⟩ 句子B $ 句子A ⟨e⟩
- 选择题(Multiple Choice) 在选择题任务中,模型需要从多个候选答案中选择一个最可能的正确答案,例如问答(Question Answering,QA)和常识推理(Commonsense Reasoning)。
“For these tasks, we are given a context document z zz, a question q qq, and a set of possible answers { a k } \{a_k\}{a
k
}. We concatenate the document context and question with each possible answer, adding a delimiter token in between to get $[z; q; $; a_k]$. Each of these sequences are processed independently with our model and then normalized via a softmax layer to produce an output distribution over possible answers.”此时的输入通常包括三个部分,以问答任务为例:
- 上下文文档 z zz :问题的背景信息。
- 问题 q qq :需要解答的问题。
- 候选答案集 a_{k}:多个可能的答案。
⟨s⟩文档z 问题q $ 答案a_1 ⟨e⟩
⟨s⟩文档z 问题q $ 答案a_2 ⟨e⟩
⋮
⟨s⟩文档z 问题q $ 答案a_k ⟨e⟩
这些序列会被独立处理,最后通过 softmax 归一化生成概率分布。
1.6 训练细节
无监督预训练(Unsupervised pre-training)
在预训练阶段,模型的目标是最大化未标注语料的语言建模函数:
$ L_1(\mathcal{U}) = \sum_i \log P(u_i \mid u_{i-k}, \ldots, u_{i-1}; \Theta) $
其中:
- : 未标注的文本语料。
- : 第 个词。
- : 上下文窗口的大小(即当前词基于前 个词预测)。
- : 模型参数。
具体流程
输入嵌入
将输入序列 映射到嵌入空间:
$ h_0 = U W_e + W_p $
- : 词嵌入矩阵。
- : 位置嵌入矩阵。
- : 初始输入的嵌入表示。
多层 Transformer 编码
输入嵌入 通过 层 transformer_block 逐层处理:
$ h_l = \texttt{transformer_block}(h_{l-1}) ; \forall i \in [1, n] $
- : 第 层的输出。
预测下一个词
最后一层的输出 被映射回词汇表维度,生成下一个词的概率分布:
$ P(u) = \texttt{softmax}(h_n W_e^T) $
- : 词嵌入矩阵的转置,将隐藏状态映射回词汇表。
softmax: 归一化概率分布。
1.7 数据集
使用 BooksCorpus 数据集56,包含大约 7,000 本未出版的书籍,数据主要从电子书分发平台 Smashwords 抓取。
BERT 预训练时除了 BooksCorpus 数据集(8 亿词元)外,还使用了英文维基百科(English Wikipedia, 25 亿词元),所以 BERT 的训练资料大概为 GPT 的四倍。 “… 所以它在这个数据集上训练了一个比 GPT 大三倍的模型 (BERT LARGE) 也是可以理解的”
使用 ftfy 库清理原始文本,标准化标点符号和空白字符,然后使用 spaCy 分词器。
使用 Byte-Pair Encoding (BPE) 进行子词分解,词汇表大小为 40,000。
1.8 超参数设置
Transformer 相关
层数 $ n_{layers} = 12 $:Transformer 解码器的层数。
我们训练了一个具有遮蔽自注意力头的12层仅解码器Transformer(状态维度为768,注意力头数为12)。
隐藏层维度 $ d_{model} = 768 $:每个隐藏层的维度为768。
注意力头数 $ n_{heads} = 12 :每层的多头注意力机制包含12个注意力头,每个头的维度为64。 12 \times 64 = 768 $。
上述数学符号与GPT-3的表2-1保持一致。
前向层维度:Transformer中FFN的隐藏层维度为3072。
Dropout率:残差连接、嵌入层和注意力中均设置为0.1。
总参数量:约117M。
其他配置
训练轮数:100。
批量大小:64。
最大序列长度:512。
优化器:Adam。
学习率调度:
初始学习率为0,在前2000步线性增加至最大值 $ 2.5 \times 10^{-4} $。之后采用余弦衰减策略逐渐减小学习率。与Transformer一样有线性增加热身的过程,但具体的衰减方式和热身步数不同。
L2正则化:权重 $ w = 0.01 $。
激活函数:GELU(Gaussian Error Linear Unit)。
位置嵌入:采用可学习的位置嵌入矩阵,而非原始Transformer中的正弦嵌入。
1.9 有监督微调
在预训练阶段完成后,模型可以根据具体的下游任务进行微调。假设我们现在有一个标注数据集 C,其中每个样本包含一个输入序列 x = (x^1, …, x^m) 和对应的标签 y。此时的目标是最大化标签 y 在输入序列 x 下的条件概率,表示为:
L_2(C) = ∑_(x,y) log P(y | x^1, …, x^m)具体流程涉及特定任务的输入处理,例如:
- 文本分类:输入处理为 ⟨s⟩ 文本 ⟨e⟩。
- 文本蕴含:输入处理为 ⟨s⟩ 前提 $ 假设 ⟨e⟩。
- 语义相似性:输入处理有两种形式,一种是 ⟨s⟩ 句子A $ 句子B ⟨e⟩,另一种是 ⟨s⟩ 句子B $ 句子A ⟨e⟩(注意这里句子A和句子B的顺序可以互换,具体取决于数据集的设计)。
- 选择题:输入处理为 ⟨s⟩ 上下文 $ 问题 $ 答案 ⟨e⟩。
微调阶段的目标是优化以下条件概率:
P(y | x^1, …, x^m) = softmax(h_l^m W_y)其中:
- 表示输入序列 x = (x^1, …, x^m) 经过预训练模型的最后一层隐藏状态。上标 m 代表位置。
- 是线性层的权重矩阵,该层接在预训练模型之后,用于将隐藏状态 映射到标签空间。
可以理解为预训练模型后接一个线性层,比如对于二分类任务,对应的代码是 nn.Linear(hidden_size, 2)。这个线性层直接输出最终的预测结果。
3 辅助目标
为了提高泛化能力和加速收敛,微调阶段还引入了预训练的语言建模目标函数作为辅助,最终的目标函数如下:
其中:
- $ L_2(C) $:主要任务的目标函数。
- $ L_1(C) $:辅助任务的目标函数。
- $ \lambda $:辅助目标函数的权重,用于平衡两个目标函数之间的相对重要性。
辅助目标函数的意义
特征增强:通过多任务或自监督学习,引导模型捕捉更通用的特征。
训练稳定性:缓解梯度消失/爆炸(如中间层监督)或对抗训练中的模式崩溃。
数据效率:利用无标签数据(自监督)或跨任务信息(多任务),减少对标注数据的依赖。
泛化能力:通过正则化或领域对齐,提升模型在未见数据上的表现。
1.10 相关设置
微调阶段对12个下游任务进行了实验,按照之前的分类如下:
- 数据集文本分类:Stanford Sentiment Treebank-2 (SST-2)、Corpus of Linguistic Acceptability (CoLA)。
- 文本蕴含:SNLI、MultiNLI、Question NLI、RTE、SciTail。
- 语义相似性:MSR Paraphrase Corpus (MRPC)、Quora Question Pairs (QQP)、STS Benchmark (STS-B)。
- 选择题:RACE、Story Cloze。
超参数设置(大多数任务)
除了以下超参数,其余均复用预训练阶段的参数设置:
- 微调轮数:3
- 批量大小:32
- 学习率调度:热身步数为训练总步数的0.2%。最大学习率调整为6.25 × 10^(-5),热身后采用线性衰减策略。
- Dropout率:分类器层(即预训练模型之后的线性层)设置为0.1。
- 辅助目标权重:λ = 0.5
到目前为止,还看不到ChatGPT的影子,因为针对不同的任务还需要进行微调,不能简单地直接用对话的形式获取答案。即便论文后续有提及Zero-shot,但实际效果一般。
关于Zero-shot
其实Zero-shot并非GPT-2才引入,在GPT-1中(第7页的Zero-shot Behaviors部分)就已经探讨了生成式预训练模型的Zero-shot性能,即模型在没有针对某些特定任务进行微调的情况下,也能通过预训练过程中学习到的知识直接完成这些任务。
“A hypothesis is that the underlying generative model learns to perform many of the tasks we evaluate on in order to improve its language modeling capability and that the more structured attentional memory of the transformer assists in transfer compared to LSTMs. ”
论文假设,预训练语言模型的生成目标让模型在学习语言建模能力的过程中,掌握了大量任务相关的语言知识。
Transformer 架构的结构化注意力机制(Structured Attentional Memory)相比于 LSTM 具有更好的迁移性。
“We designed a series of heuristic solutions that use the underlying generative model to perform tasks without supervised finetuning.”
作者设计了一系列启发式方法,通过直接使用生成预训练模型(无需监督微调)解决不同下游任务。
“For SST-2 (sentiment analysis), we append the token very to each example and restrict the language model’s output distribution to only the words positive and negative and guess the token it assigns higher probability to as the prediction…”
以情感分析任务为例,对于输入:
The movie was incredibly entertaining.
增加 very:
The movie was incredibly entertaining. very
限制生成的输出仅包含“positive”和“negative”,最后根据预测的概率确定情感。
下图展示了模型在不同任务上的零样本性能随预训练迭代次数的变化趋势。性能指标归一化到随机猜测与当前 SOTA 之间:
可以看到,随着训练的进行,任务性能稳定增长,但离 SOTA 还有不小的差距。
2 GPT2
GPT-2 的整体设计思想相较于 GPT-1 没有变化,但通过模型规模的扩展和数据集的优化,在零样本学习(Zero-Shot Learning)上迈出了一大步。此前该领域的模型或受限于架构或受限于规模,性能远不如 GPT-2。
关键改进
- 更大的数据集
GPT-2 使用了 WebText 数据集进行训练。WebText 的文本来源是 4500 万个经过 Reddit 用户过滤后的网页链接(至少有 3 karma,karma 可以视为点赞数),经过去重和清理后,最终包含 800 万篇文档,总计约 40GB 的文本(GPT-1 数据集的大小约为 1GB)。为了避免评估数据的“泄漏”,数据集还特意去除了常见的数据来源(比如维基百科)。同时,由于数据集的变化,词汇表从 40,000 扩展到了 50,257。值得一提的是,GPT-2 采用了字节级的 BPE (Byte-level Byte Pair Encoding) 进行分词(GPT-1 使用的是传统的 BPE)。
- 更大的模型
GPT-2 的参数规模(15 亿参数)远超其前身 GPT-1(1.1 亿参数)以及当时的主流模型(如 BERT_LARGE 的 3.4 亿参数)。但模型主体架构并没有修改,只是调整了一些超参数:
- 层数 n_{layers}:12 → 48
- 隐藏层维度 d_{model}:768 → 1,600
- 最大序列长度:512 → 1,024
- 批量大小:64 → 512
另外,还引入了一些细节优化:
- 层归一化(Layer Normalization):调整至每个子模块的输入端(Pre-Norm),类似于预激活残差网络,同时在最后的自注意力模块后增加额外的层归一化。
- 残差权重初始化:采用了 1 / \sqrt{N} 的权重缩放因子,其中 N 是残差层的深度。
这些改进共同提升了 GPT-2 的性能和泛化能力。

其中,最小的模型(117M)对标 GPT-1,第二个模型(345M)对标 BERT LARGE,最大的模型(1152M)称为 GPT-2,它的另一个名字是 GPT2-XL。
2.2 零样本学习(Zero-shot Learning)
GPT-2 的创新在于对零样本学习的进一步探索。GPT-1 微调时引入了三种特殊符号: ⟨ s ⟩ \langle s \rangle⟨s⟩, $, ⟨ e ⟩ \langle e \rangle⟨e⟩,这些符号在预训练时并没有见过,所以会在微调的时候学习表示。而 GPT-2 不再引入这些特殊符号,采用与 GPT-1 预训练数据格式更相似的自然输入格式(其实就是不做多余操作,单纯的预训练),这也是后续文献常提及以及我们现在耳熟能详的 Prompt,作者给出了两个例子:
- 翻译:translate to French, English text, French text。

- 阅读理解:answer the question, document, question, answer
正如论文标题 「Language Models are Unsupervised Multitask Learners」 所暗示的,在 GPT-2 的原始论文中,模型并未针对任何下游任务进行有监督的微调(fine-tuning),而是直接在大规模文本上进行预训练,然后在各种 NLP 任务上测试性能。
所以 Zero-shot 或许可以片面地理解为只进行预训练。
Q1:什么是 Pre-Norm?和 GPT-1 的区别?

GPT-1 和 GPT-2 的区别
GPT-1:Post-Norm,层归一化放置在残差连接之后。 GPT-2:Pre-Norm,层归一化放置在残差连接之前。
def forward(self, x, sublayer):
# 子层的输出 + 残差连接后,进行归一化
return self.norm(x + sublayer(x))
def forward(self, x, sublayer):
# 输入先进行归一化,再传入子层,最后进行残差连接
return x + sublayer(self.norm(x))3. GPT-3
GPT-3 关键改进: 秉承传统:更大的数据集和更大的模型。
3.1 摘要
人类有时只需少数示例或简单说明,便能轻松应对全新的语言任务,然而当前的自然语言处理系统仍面临巨大挑战。很多情况下,系统仍需通过特定任务的微调才能获得出色的效果。在这个挑战的推动下,OpenAI的研究人员努力改进了GPT-2 模型的有效性,并发布了GPT-3模型。
GPT-3是一个拥有1750亿模型参数的自回归语言模型。 与GPT-2相比,GPT-3的参数量翻了116倍。与此同时,GPT-3采用了GPT-1最初提出的Few- shot设置,即模型在处理子任务时不再依赖大量样例,而是在可控范围内给出一些样本。这种设置的成本非常低,但却能为模型提供足够的信息。最令人惊叹的是,GPT-3在任何任务上都无需任何梯度更新或微调,只需通过与模型的文本交互来指定任务和展示少量样本。
GPT-3在多个自然语言处理任务中展现出了惊艳的性能 ,如翻译、问答和填空,同时还能够应对那些需要即时推理或领域适应的挑战,如拼写校正、引入新词和进行三位数算术运算。OpenAI 的科研人员发现,增加语言模型的规模可以极大地提升任务无关的少样本学习性能,有时甚至能够与当前最领先的微调方法媲美,这一突破在当时引发了极大的关注和赞誉。
3.2 引言
为了在各类任务中实现卓越性能,通常需要对特定任务的数据集进行大规模微调,这涉及数千到数十万个需要人工标注的数据集。然而,消除这种限制是可取的,原因如下所述:
首先,从实践角度来看,为每个新任务收集大规模标记示例数据集的需求限制了语言模型的适用性 。语言任务的种类繁多,涵盖了从语法纠错到生成抽象概念示例,再到批评短篇故事等各种内容。对许多任务而言,要收集大规模的监督训练数据集往往具有挑战性,特别是当必须为每个新任务重复这个过程时。
其次,训练数据中的偶然相关性与模型表达能力和训练分布的狭隘性之间存在直接关系,这对于预训练后进行微调的模型来说可能带来问题 。尽管这些模型在预训练阶段被设计得很大,能够吸收大量信息,但在非常狭隘的任务分布上进行微调。有证据表明,这种范式下的泛化能力可能较弱,因为模型过于特定于训练分布,并且在其之外的泛化能力不强。
最后,人类在学习大多数语言任务时并不需要大规模的监督数据集 。仅仅凭借自然语言中的简短指令或少数示例,人类就能够在新任务上胜任并达到合理水平。这种适应性不仅揭示了当前自然语言处理技术的限制,而且具有实际优势。它使人类能够无缝地混合或切换多个任务和技能,例如在长时间对话中进行加法运算。为了广泛应用,研究者们希望有朝一日自然语言处理系统也能具备类似的灵活性和普适性。
为了解决上述问题,OpenAI的研究人员训练了一个巨大的自回归语言模型,拥有着惊人的1750亿参数,即GPT-3 。在应对各类后续任务时,他们主要采用了Few-shot、One-shot和Zero- shot这三种不同的设定策略,并在不需要对模型进行任何形式微调的情况下取得了引人注目的成果。简言之,这意味着通过提供一些任务样例(即上下文信息),该模型能够自主探索并掌握处理这些任务的能力 。这种能力主要来源于以下两方面:
第一,通过在语言模型的训练中培养广泛的技能和模式识别能力,然后在推理过程中利用这些能力来适应或识别所需的任务 。
如Figure 1.1所示,每个样本来自于不同的任务,涵盖了各种领域,如加法运算、语法纠正和翻译。这些任务提供了大量的训练数据,为模型提供了广泛的语言样本。通过在这些多样化的数据上进行训练,模型能够理解和处理各种任务。从上下文学习的角度来看,对于同一任务的处理,模型能够通过上下文中的信息进行准确推断,从而提高任务的效果。在这个过程中,模型能够从上下文中提取相关的知识和洞察,以支持对不同任务的有效适应。
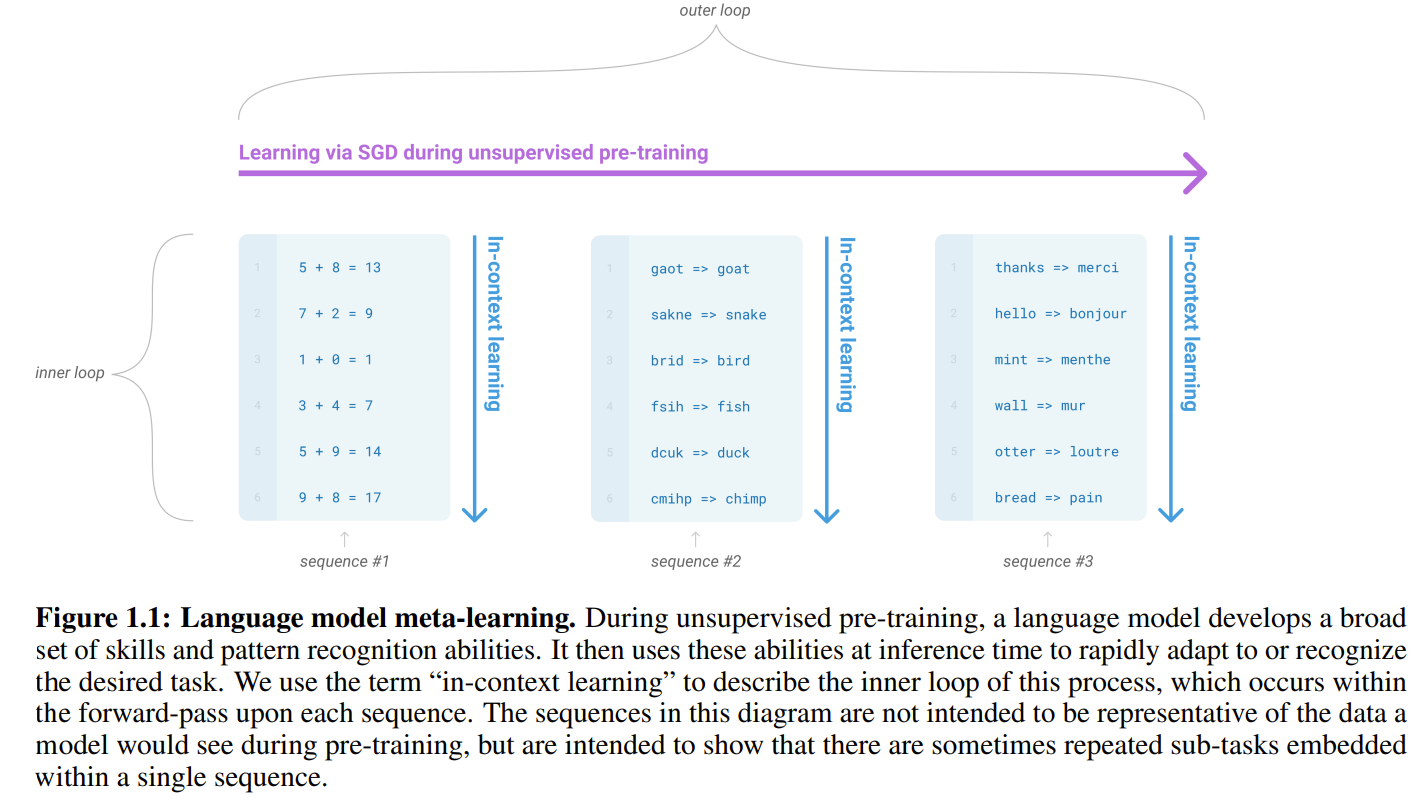
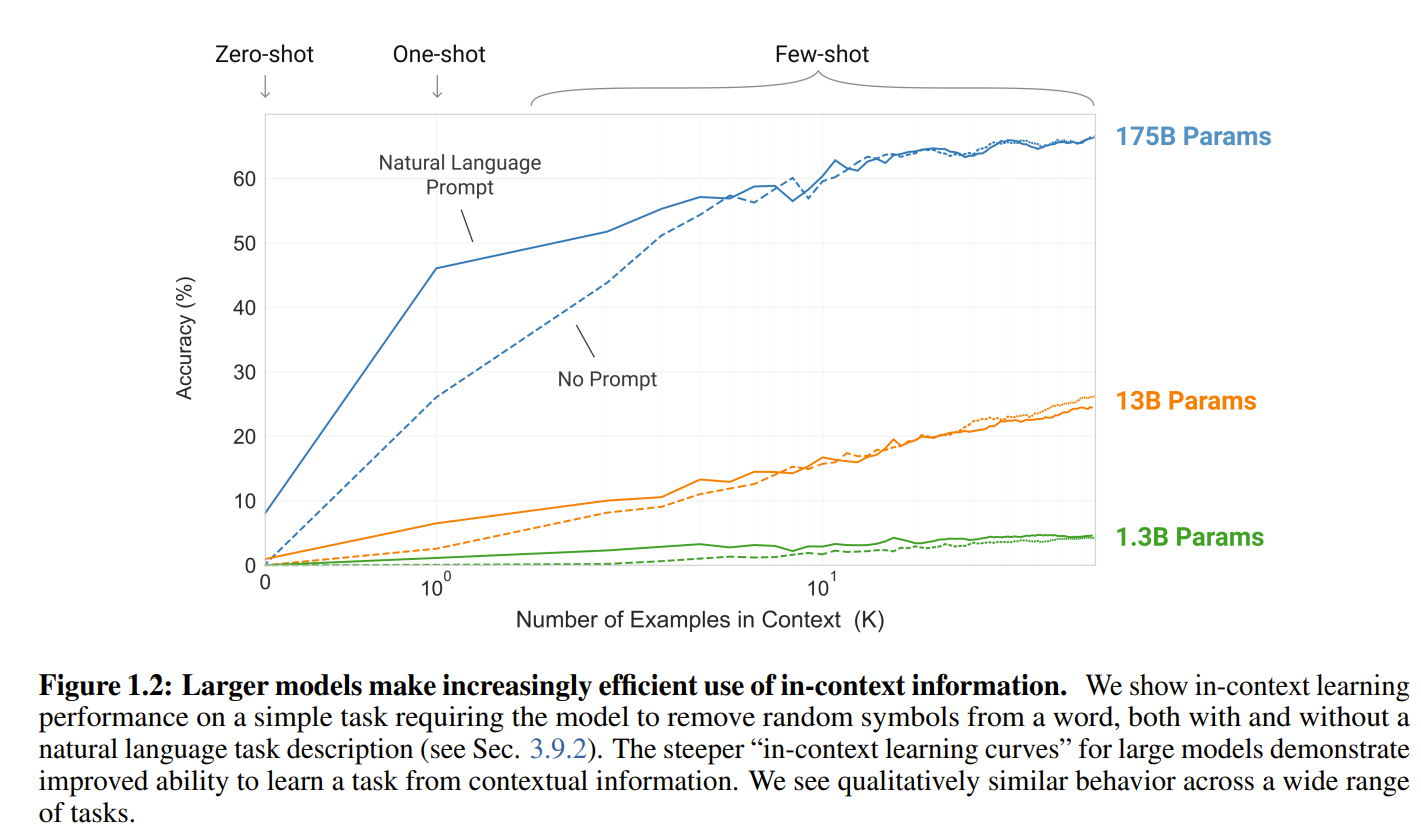
第二,增加语言模型的参数规模,通过模型参数规模的显著增加,可以提升自然语言处理任务的性能 。
如Figure 1.2所示,随着模型参数规模的增加,上下文学习能力会获得类似的强大增益。
3.3 训练数据集
3.3.1 数据集概述
GPT-3的训练需要大量的训练数据,这些数据主要来源于精心筛选过的CommonCrawl、WebText数据集的扩展版本、两个基于互联网的图书语料库(Books1和Books2)和英语维基百科数据集 。
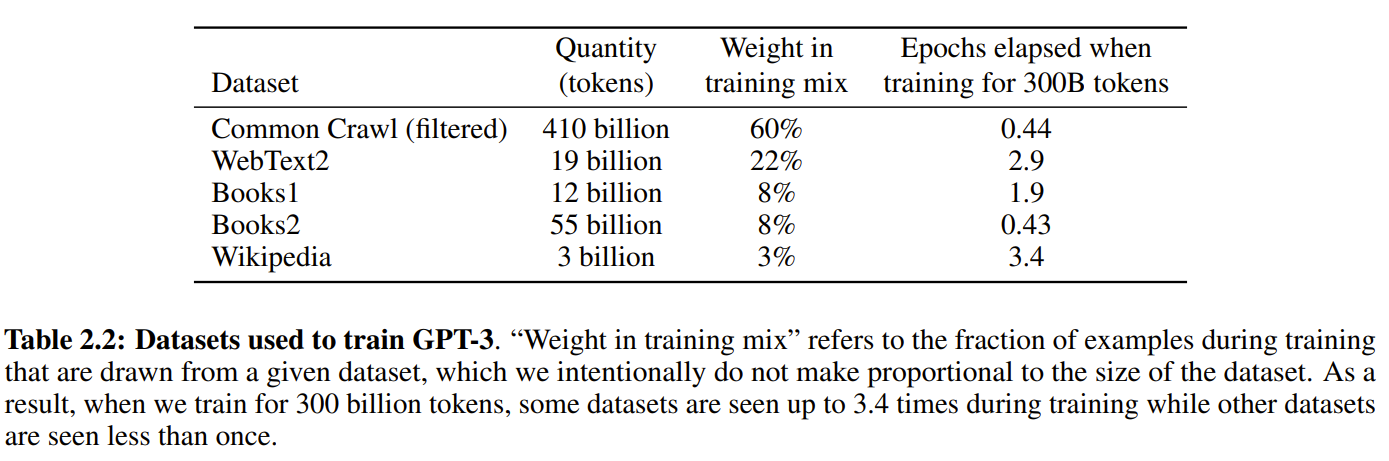
Table2.2呈现了最终训练数据集的混合情况。可以看到,在训练过程中,研究人员并非按照数据集大小的比例进行采样,而更倾向于频繁采样质量较高的数据集。因此,CommonCrawl和Books2数据集在训练中的采样次数不到一次,而其他数据集则采样2-3次。这种方法在一定程度上容忍了轻微的过拟合,以换取更高质量的训练数据。
GPT-3 的训练数据集来自 Common Crawl、WebText2、Books1、Books2 和 Wikipedia,论文的表 2.2 列出了它们的规模、在训练中的权重分布以及训练 3000 亿 tokens 时经过的轮次:
3.3.2 数据集详情
| 数据集 | 数据量(tokens 数) | 训练混合中的权重 | 训练 3000 亿 tokens 时的轮次 |
|---|---|---|---|
| Common Crawl(过滤后) | 约 4100 亿 | 60% | 0.44 |
| WebText2 | 约 190 亿 | 22% | 2.9 |
| Books1 | 约 120 亿 | 8% | 1.9 |
| Books2 | 约 550 亿 | 8% | 0.43 |
| Wikipedia | 约 30 亿 | 3% | 3.4 |
需要注意的是,尽管 Common Crawl 是规模最大的数据集,数据量远超其他来源(是 WebText2 的 21.58 倍),但由于质量参差不齐,其训练权重被适当降低,仅为总权重的 60%,而较小但质量更高的 WebText2 则分配了 22% 的训练权重。
3.3.3 对于数据集 Common Crawl 的处理
Common Crawl 是一个非盈利组织,会定期抓取互联网上的网页数据并免费开放给研究者使用。为了准备更大的数据集以匹配更大的模型,OpenAI 团队从 Common Crawl 中下载了 2016-2019 年的 41 个数据分片,总量约 45TB(压缩后)。在经过一系列自动化过滤、重新采样和去重处理后,最终得到约 570GB 的文本,对应约 4100 亿 Byte-Pair Encoding (BPE) 子词。
- 自动过滤 (Automatic Filtering)
训练集与分类器 为了从原始 Common Crawl 中挑选更高质量的文档,研究团队采取了以下步骤:
- 数据集准备:将高质量语料(如 WebText、Wikipedia、以及 web books corpus)合并为“正例”数据集,并将未经过滤的 Common Crawl 用作“负例”。
- 特征提取:利用 Spark 的标准分词器(Tokenizer)和 HashingTF 提取文本特征。
- 分类器训练:以此特征训练 Logistic Regression(逻辑回归)分类器,为每篇文档打分。得分越高,表示该文档越“接近”高质量语料;得分较低则表明该文档的质量“可能”欠佳。
重新采样 (Resampling) 与 Pareto 分布
基于上述“质量分数”,研究团队利用以下条件进行重新采样:
\texttt{np.random.pareto}(\alpha) > 1 - \texttt{document\_score}其中,(\alpha = 9)。文档得分越高,越容易保留;但低分文档也有一定概率被保留,以维持多样性。以下代码示例有助于理解上述概念:
import numpy as np
def filter_rate(doc_score, alpha=9, trials=100000):
"""
doc_score: 文档分数 (0 - 1)
alpha: Pareto 分布的形状参数
trials: 模拟采样次数
"""
# 1. 生成很多个 Pareto(α=9) 随机数
samples = np.random.pareto(alpha, size=trials)
# 2. 计算阈值
threshold = 1 - doc_score
# 3. 看看有多少随机数满足:sample > threshold
pass_count = np.sum(samples > threshold)
return pass_count / trials
# 测试不同的 document_score
scores = [0.0, 0.2, 0.5, 0.8, 0.9]
for s in scores:
rate = filter_rate(s)
print(f"doc_score={s}, 通过过滤的模拟比例={rate:.4f}")doc_score=0.0, 通过过滤的模拟比例=0.0021
doc_score=0.2, 通过过滤的模拟比例=0.0051
doc_score=0.5, 通过过滤的模拟比例=0.0268
doc_score=0.8, 通过过滤的模拟比例=0.1950
doc_score=0.9, 通过过滤的模拟比例=0.4243注意:上述代码仅为示例,实际使用时需根据具体数据和需求进行调整。
输出:
- 当 doc_score=0,约 0.2% 的保留率。
- 当 doc_score=0.9,约 42% 的保留率。
核心思路:
if np.random.pareto(alpha) > 1 - document_score:
keep_doc = True
else:
keep_doc = False- 模糊去重 (Fuzzy Deduplication) 为进一步提升模型质量并降低过拟合风险,研究团队还对各训练集做了模糊去重(使用和上面分类相同的特征):
- 在 Spark 中使用 MinHashLSH(配置 10 个哈希),利用与上面分类相同的特征来检测文档间的相似度,对相似度较高的文档进行删除。
- 同时将 WebText 中出现的内容从 Common Crawl 里删除(方式同上)。
整体来看,模糊去重将减少 10% 的数据量。
在论文中提到尽管他们尝试去重(训练集和测试集之间,train-test overlap),但因为某些 bug,有可能存在少量测试集内容被模型“见”过,从而造成一定的数据泄漏。而由于训练成本太大,他们没法重来,论文的第 4 节评估了数据泄露的影响。
3.4 模型和架构
GPT-3采用与GPT-2相同的模型和架构,唯一的区别在于GPT-3在Transformer层中引入了交替的稠密和局部带状稀疏注意力模式,类似于Sparse Transformer。
为了深入探究模型规模对学习性能的影响,研究人员训练了8种不同规模的模型,涵盖了从1.25亿个参数到1750亿个参数的三个数量级范围 。其中,最庞大的模型被命名为GPT-3。
在Table2.1中展示了8个模型的规模和架构。其中,nparams代表可训练参数的总数,nlayers表示Transformer的总层数,dmodel指每个bottleneck layer中的神经元数量,而前馈层的大小是bottleneck layer大小的四倍,即 ,dhead表示每个注意力头的维度。
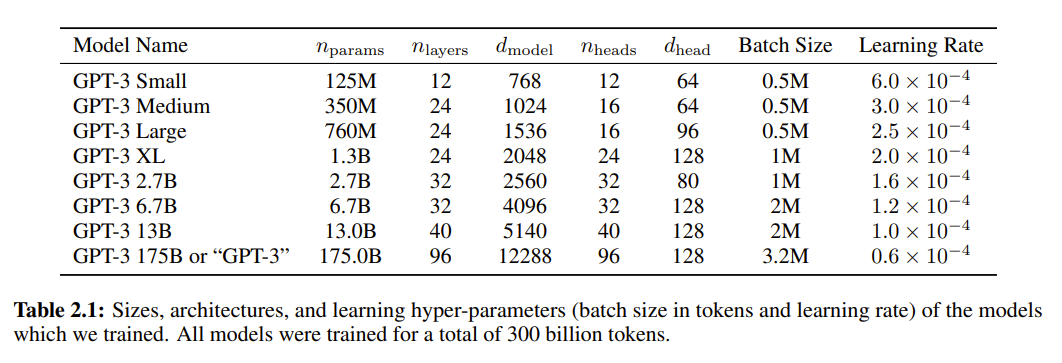
所有的模型的上下文窗口都为nctx=2048个tokens。为了减少节点之间的数据传输,研究人员将模型根据其深度和宽度分割到不同的GPU上。具体的模型架构参数是根据计算效率和负载均衡在GPU上选择的。
3.5 训练过程
为了在训练更大的模型时避免内存耗尽,GPT-3在训练过程中采用了一种模型并行化的混合方法,既在每个矩阵乘法运算内部采用模型并行化,又在网络的各个层之间采用模型并行化 。所有模型都是在由微软提供的高带宽集群中的V100 GPU上进行训练的。
GPT-3在训练过程中采用了Adam优化器,参数设置为β1 = 0.9,β2 = 0.95,ε = 10-8,为了控制梯度的范围,将梯度的全局范数裁剪为1.0。
在处理2600亿个tokens的过程中,会通过余弦衰减逐步降低学习率至初始值的10%(即:在处理完2600亿个tokens后,学习率会继续以原始学习率的10%进行训练)。此外,在训练的前40-120亿个tokens中,会逐渐增加BatchSize大小,从较小的值(32k个tokens)增加到设定的最大值。具体参数设置可见Table 2.1。
为了减小过拟合现象,采用了无替换的数据采样策略,直到达到一个epoch的边界。所有模型都使用0.1的权重衰减进行轻微的正则化。在训练过程中,始终使用2048个tokens的上下文窗口序列进行训练,当文档长度小于2048个tokens时,我们将多个文档打包成一个序列,以提高计算效率。 序列中的多个文档通过特殊的文本结束标记进行分隔,为语言模型提供了上下文无关信息的推断。这种方式实现了高效的训练,无需进行特殊的序列屏蔽操作。
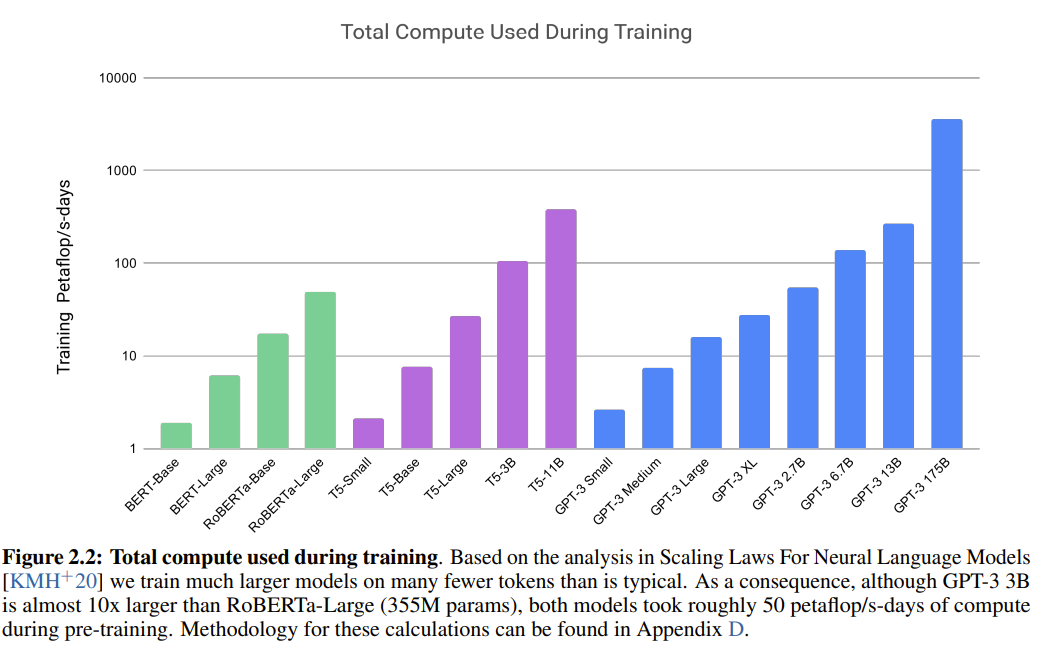
Figure 2.2展示了GPT-3在训练过程中的总计算量。显而易见,随着模型参数规模的增加,计算量的也在显著增加。
3.6 上下文学习的三种设置
GPT-3在训练完成之后,就可以使用Few-Shot、One-Shot和Zero- Shot三种不同的方式在特定任务上进行使用。值得注意的是,GPT-3在特定任务上使用时无需进行微调或参数更新。这三种使用方式的简单介绍如下所示:
• Few-Shot(FS): 模型在推理时给出K个任务示例作为上下文信息,同时提供任务的自然语言描述,但不允许模型进行权重更新。通常将K设置在10到100的范围内,以适应模型的上下文窗口。
• One-Shot(1S): 模型在推理时通过提供一个任务示例作为上下文信息,同时还有任务的自然语言描述。这种方式最接近于人类在解决某些任务时所使用的方式。
• Zero-Shot(0S): 不提供任何上下文信息,模型只给出一个描述任务的自然语言指令。
下图以英语翻译成法语的示例说明了Few-Shot、One-Shot和Zero-Shot这三种方法,并展示了传统Fine-tuning方法的一般流程。
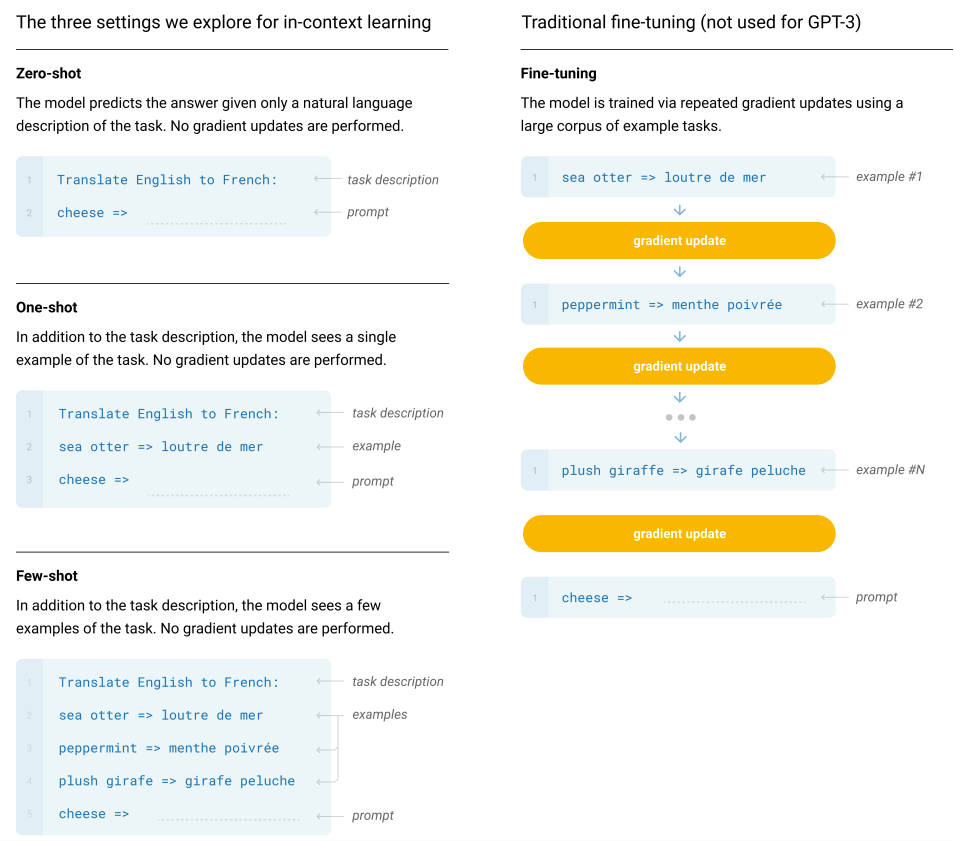
注释:In-Context Learning 是通过提示(Prompt)完成任务,而微调是通过训练更新参数来适应任务。一个不更新参数,一个更新参数。一个是 eval,一个是 train。
3.7 GPT-3的局限性
尽管与GPT-2相比,GPT-3的性能有了显著的提升,但仍然存在以下局限性:
- GPT-3在文本合成任务中偶尔会出现语义上的重复,随着段落变长,连贯性下降,同时还存在自相矛盾和不相关的句子。 而对于"常识物理"问题,例如"奶酪放进冰箱是否会融化",GPT-3表现困难。
- GPT-3存在结构和算法上的限制 ,GPT-3专注于自回归语言模型的上下文学习行为,模型未包括双向架构或其他训练目标,这种设计决策可能导致在实际受益于双向性的任务上性能较差。
- GPT-3的训练目标对每个token赋予相同的权重,缺乏对于预测中什么是最重要和什么是次要的概念。
- GPT-3缺乏与其他领域(如视频或现实世界的物理交互)相关联的背景知识和大量上下文信息,知识的缺失 会对模型性能造成影响。
- GPT-3少样本学习面临的一个不确定性 是,在推理过程中难以确定模型到底是“从零开始”学习新任务,还是仅仅在区分和识别训练期间学到的任务。
- 由于GPT-3的庞大参数规模,不论是训练还是推理部署过程都具备高昂的成本 和不便之处,这或许对目前这种规模的模型在实际应用中带来一定的挑战。
- GPT-3训练数据中的偏见可能导致模型生成的内容变得刻板化或带有偏见。
3.8 总结
GPT-3是一个拥有1750亿个参数的语言模型,与15亿参数的GPT-2相比,GPT-3更像是一个暴力出奇迹的结果。GPT-3在Zero-shot、One-shot和Few-shot 的设置下,在众多自然语言处理任务中展现出强大的性能。
本文详细探讨了GPT-3 的基本原理以及其所面临的局限性。尽管GPT-3存在一些限制,但它的出现印证了大规模语言模型有可能成为发展适应能力强、通用的语言系统的重要组成部分。在当前大模型盛行的时代背景下,GPT-3的工作仍具备极大的价值。
4 GPT-4
代续