1. DP(DataParalle)Summary
数据并行的概念
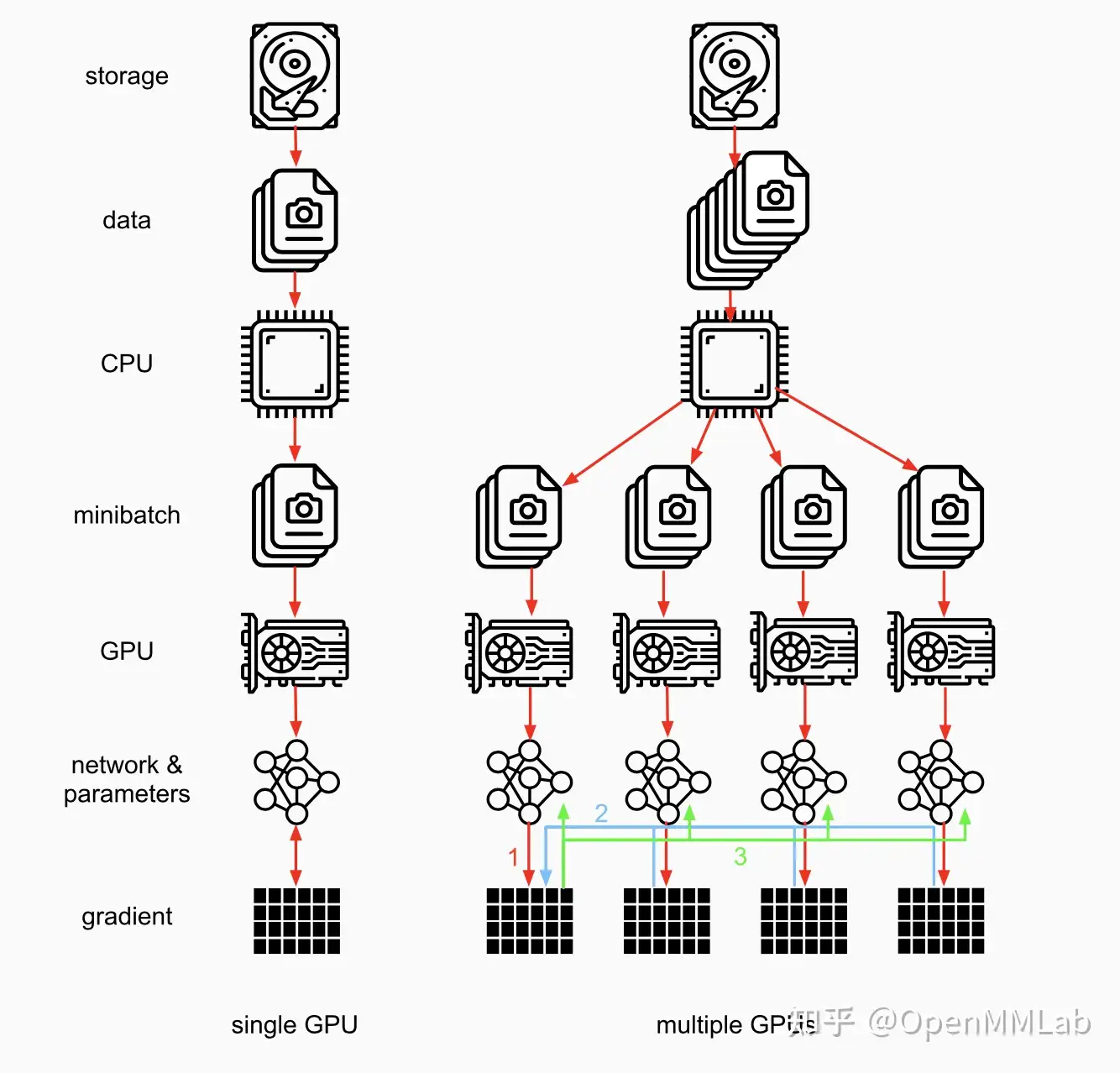
当一张 GPU 可以存储一个模型时,可以采用数据并行得到更准确的梯度或者加速训练:
即每个 GPU 复制一份模型,将一批样本分为多份输入各个模型并行计算。
因为求导以及加和都是线性的,数据并行在数学上也有效。
DP原理及步骤
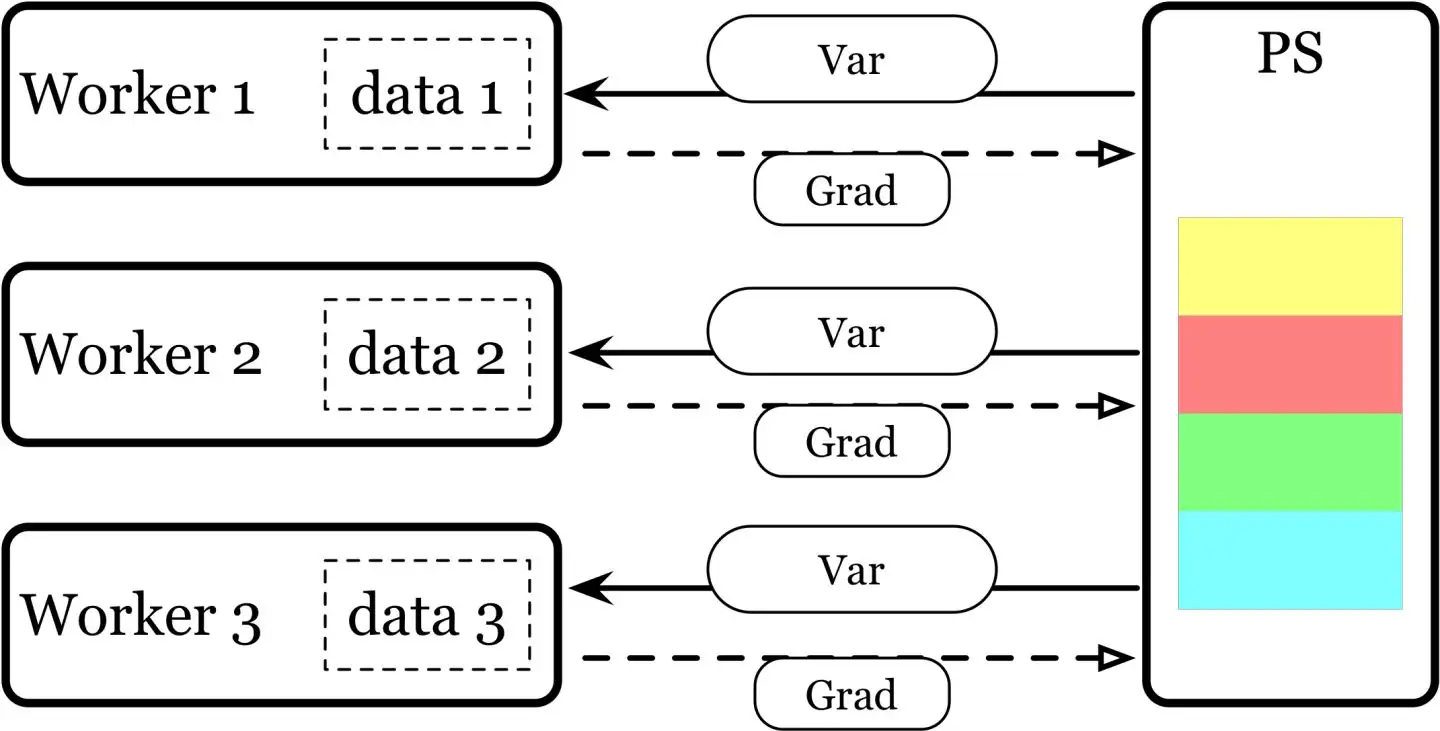
- Parameter Server 架构 --> 单进程 多线程的方式 --> 只能在单机多卡上使用;
- DP 基于单机多卡,所有设备都负责计算和训练网络;
- 除此之外, device[0] (并非 GPU 真实标号而是输入参数 device_ids 首位) 还要负责整合梯度,更新参数。
- 大体步骤:
- 各卡分别计算损失和梯度;
- 所有梯度整合到 device[0];
- device[0] 进行参数更新,其他卡拉取 device[0] 的参数进行更新;
2. code implement
pytorch 相关源码
python
import torch.nn as nn
model = nn.DataParallel(model) # 只需要将原来单卡的 module 用 DP 改成多卡
class DataParallel(Module):train mode use pytorch DP
运行 dp_hello.py
shell
python dp_hello.py
output:
>>> output: Let's use 2 GPUs!运行 dp_demo.py
shell
python dp_demo.py
result:
>>> data shape: torch.Size([64, 1, 28, 28])
>>> =============x shape: torch.Size([32, 1, 28, 28])
>>> =============x shape: torch.Size([32, 1, 28, 28])3. DP 的优缺点
- 负载不均衡:device[0] 负载大一些;
- 通信开销大;
- 单进程;
- Global Interpreter Lock (GIL)全局解释器锁,简单来说就是,一个 Python 进程只能利用一个 CPU kernel,
即单核多线程并发时,只能执行一个线程。考虑多核,多核多线程可能出现线程颠簸 (thrashing) 造成资源浪费,
所以 Python 想要利用多核最好是多进程。