1 案例展示
# install pytorch > 1.12 with cuda enabled first
git clone https://github.com/pytorch/examples.git (2d725b6ab255e05c55e0b08925f06f171aaedc0c)
cd examples/distributed/FSDP
pip install -r requirements.txt
torchrun --nnodes 1 --nproc_per_node 2 T5_training.py2 原理及流程
DDP 实现原理 vs FSDP 实现原理
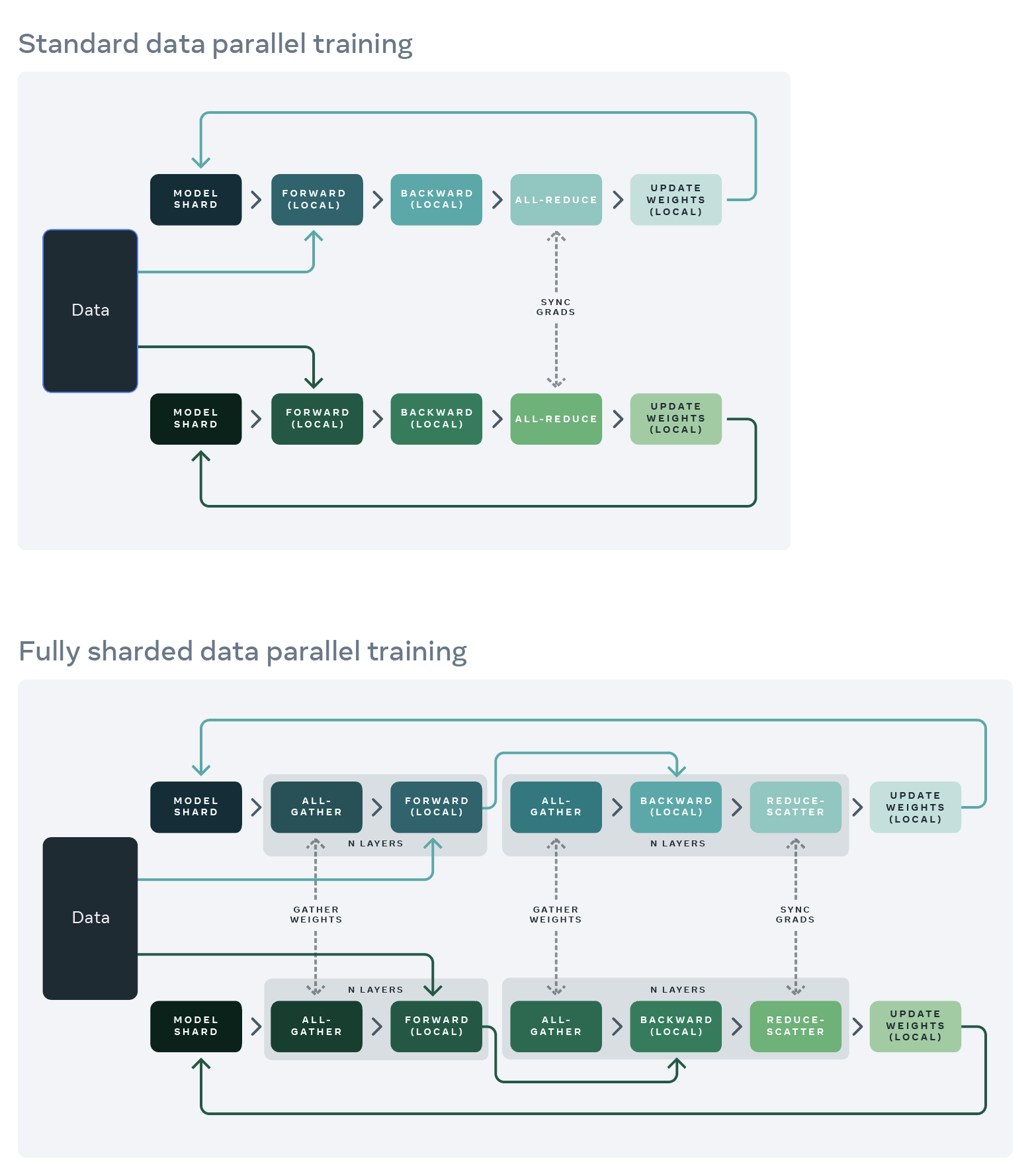
DDP 与 FSDP 流程
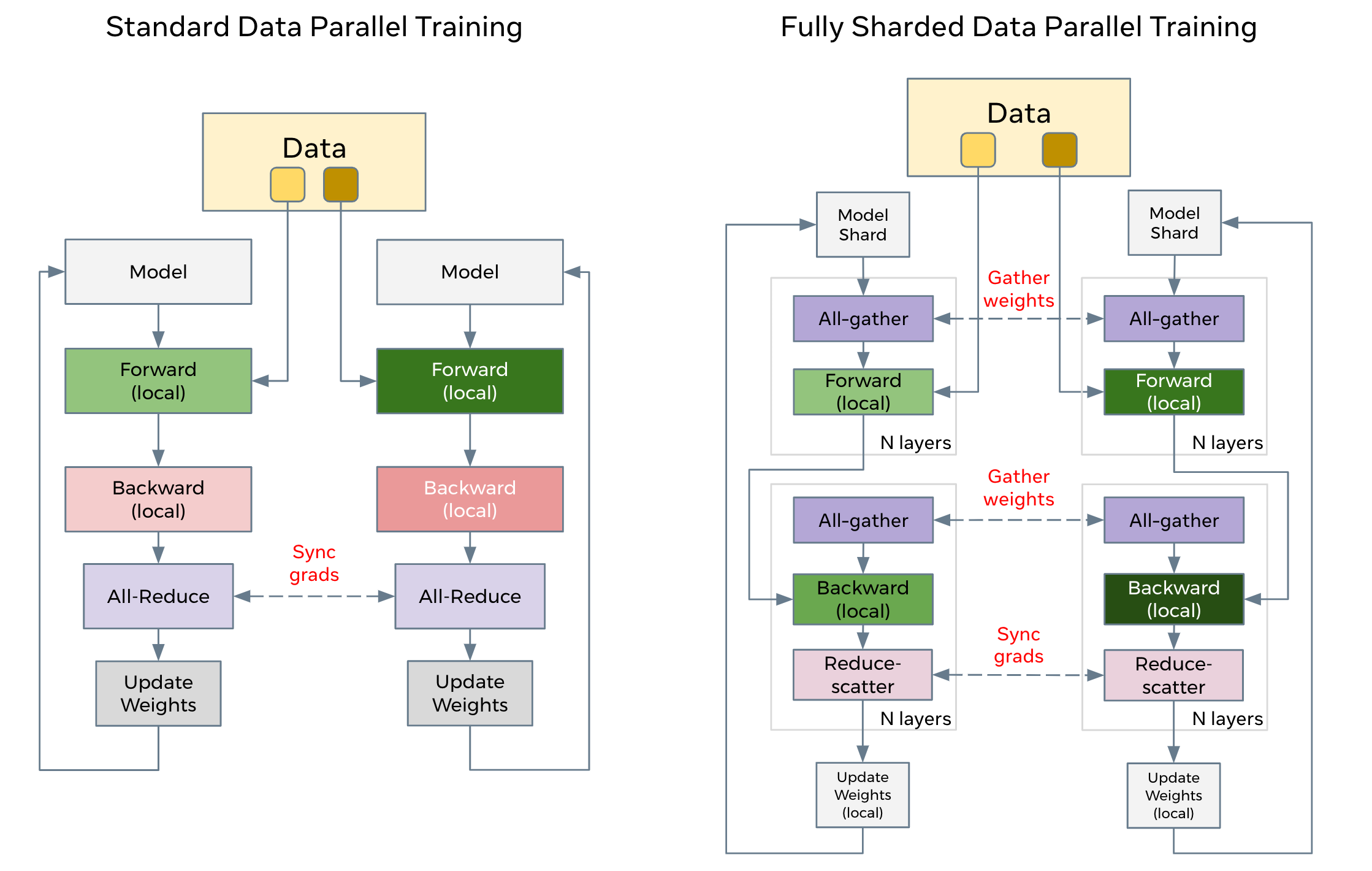
DDP 和 FSDP 通信上的不同
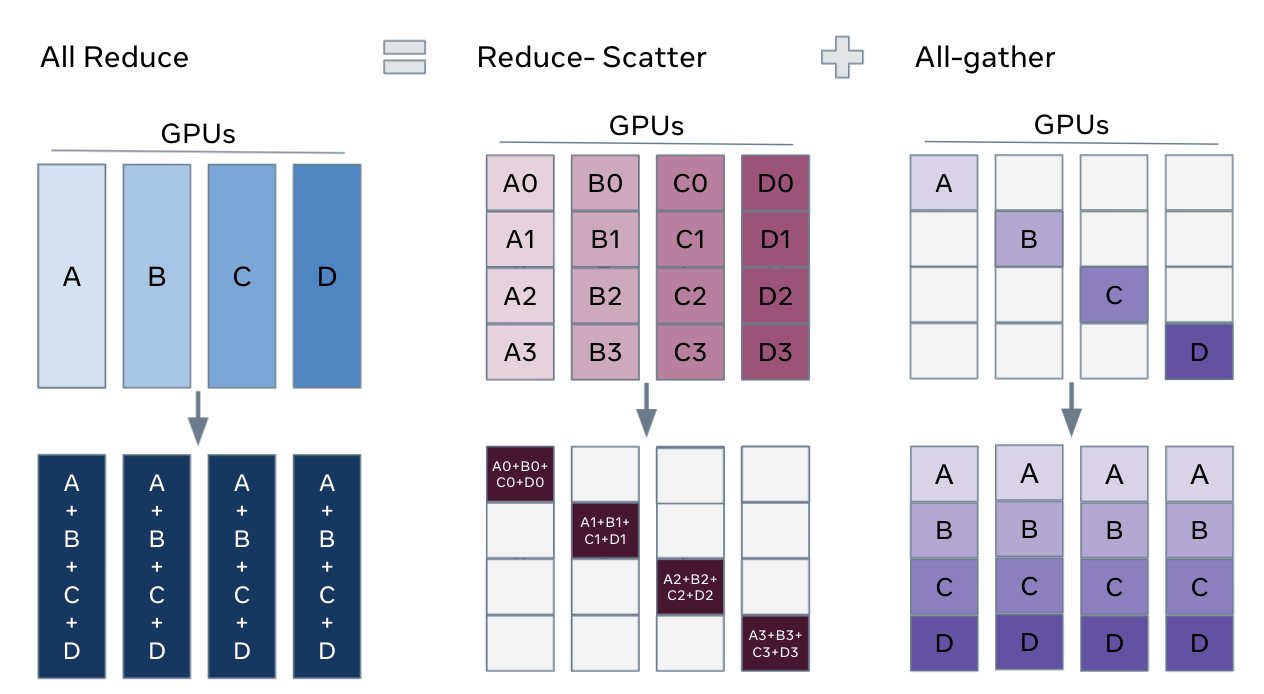
3 注意事项
- 优化器必须在模块被封装之后初始化,因为FSDP会就地分片参数,这会破坏之前初始化的优化器;
- 在使用CPU卸载时,FSDP目前不支持在 "no_sync()" 之外进行梯度累积。尝试这样做会产生错误的结果,因为FSDP将使用新的已 reduced 的梯度,而不是与任何现有梯度累积;
- 模型构造之后如何更改 parameter的名字 将导致未定义的行为;
- 传递sync_module_states=True标志要求将模块(module)放置在GPU上,或者使用device_id参数来指定FSDP将模块移动到的CUDA设备。这是因为sync_module_states=True需要进行GPU通信;
- 截至PyTorch 1.12,FSDP仅提供有限的共享参数支持(例如,将一个Linear层的权重设置为另一个层的权重)。特别是,共享参数的模块必须作为同一FSDP单元的一部分进行封装。如果您的使用情况需要增强的共享参数支持;
- 尝试运行包含在FSDP实例中的子模块的前向传递是不受支持的,并且会导致错误。这是因为子模块的参数将被分片,但它本身不是一个FSDP实例,所以它的前向传递不会适当地聚集所有参数。这可能会在尝试仅运行编码器的编码器-解码器模型时发生,并且编码器没有被封装在自己的FSDP实例中。为了解决这个问题,请将子模块封装在自己的FSDP单元中。;
- 在运行FSDP的“forward”函数之前,输入将被移动到计算设备(与FSDP模块所在的设备相同), 因此用户无需手动将输入从CPU移动到GPU。
- Dynamo将被FSDP包装的模块视为UnspecializedNNModule, Dynamo跳过了所有的FSDP代码帧, 它无法直接检查FSDP模块, Dynamo只支持使用use_orig_params=True的FSDP。
4 核心代码解读
4.1 FSDP 初始化
# FSDP 的实例化
model = torch.distributed.fsdp.FullyShardedDataParallel(model,
auto_wrap_policy=t5_auto_wrap_policy,
mixed_precision=mixed_precision_policy,
sharding_strategy=fsdp_config.sharding_strategy,
device_id=torch.cuda.current_device(),
limit_all_gathers=fsdp_config.limit_all_gathers)
# 具体类的构造函数
class FullyShardedDataParallel(nn.Module, _FSDPState):
def __init__(
self,
module: nn.Module, # 将被FSDP 包装的module
# 用于进行集体通信的进程组,也是模型分片的进程组。对于混合分片策略(例如ShardingStrategy.HYBRID_SHARD),用户可以传入一个包含表示要进行分片和复制的进程组的元组。
process_group: ProcessGroupType = None,
sharding_strategy: Optional[ShardingStrategy] = None, #配置FSDP使用的分片策略,在内存节省和通信开销之间做出权衡
cpu_offload: Optional[CPUOffload] = None, #是否启动CPU Offload 默认 None
auto_wrap_policy: Optional[Union[Callable, _FSDPPolicy]] = None, # 被wrap的策略
backward_prefetch: Optional[BackwardPrefetch] = BackwardPrefetch.BACKWARD_PRE, # 明确配置 all-gather 操作的反向预取。
mixed_precision: Optional[MixedPrecision] = None, # 为FSDP配置本地混合精度。可以设置参数、缓冲区和梯度reduce的数据类型。
ignored_modules: Optional[Iterable[torch.nn.Module]] = None, # 不进行分片的模块
param_init_fn: Optional[Callable[[nn.Module], None]] = None, # 自定义的参数初始化
device_id: Optional[Union[int, torch.device]] = None, #
sync_module_states: bool = False,
forward_prefetch: bool = False,
limit_all_gathers: bool = False,
use_orig_params: bool = False,
ignored_parameters: Optional[Iterable[torch.nn.Parameter]] = None,
):
# auto_wrap_policy (Optional[Union[Callable[[nn.Module, bool, int], bool], _FSDPPolicy]]):<br>
# 这可以是None、一个_FSDPPolicy,或者一个具有固定签名的可调用对象。如果是None,则module将只被一个顶层的FSDP实例包装,没有任何嵌套包装。
# 如果是一个_FSDPPolicy,则包装遵循给定的策略。torch.distributed.fsdp.wrap.py中的ModuleWrapPolicy是一个示例。
# 如果是一个可调用对象,则它应该接受三个参数module: nn.Module、recurse: bool和nonwrapped_numel: int,并返回一个bool值,指定当recurse=False时是否应该包装传入的module,或者如果recurse=True时遍历应该继续下去。
# 可调用对象可以添加额外的自定义参数。torch.distributed.fsdp.wrap.py中的size_based_auto_wrap_policy是一个示例可调用对象,它在其子树中的参数超过100M个元素时包装一个模块。一个好的做法是在包装后打印模型,并根据需要进行调整。
# ignored_modules (Optional[Iterable[torch.nn.Module]])
# 被当前实例忽略的模块, 模块的参数以及子模块的参数和缓冲区将被忽略。
# ignored_modules中的直接模块不应该是:class:FullyShardedDataParallel的实例,如果已经构建的子模块是:class:FullyShardedDataParallel的实例并且嵌套在这个实例下面,那么它们将不会被忽略。
# 当使用auto_wrap_policy时,或者如果参数的分片不由FSDP管理,可以使用此参数来避免按模块粒度分片特定的参数。
# param_init_fn(Optional[Callable[[nn.Module], None]]):
# 一个 Callable[torch.nn.Module] -> None,用于指定当前在元设备上的模块应该如何初始化到实际设备上.
# 请注意,从v1.12开始,我们通过is_meta检查来检测元设备上的模块,并应用默认初始化,如果未指定param_init_fn, 则在传入的nn.Module上调用reset_parameters方法,否则我们运行param_init_fn来初始化传入的nn.Module。
# 特别要注意的是,如果任何需要被FSDP包装的模块的 Parameters 的is_meta=True且未指定param_init_fn,我们假设您的模块正确实现了reset_parameters(),否则会抛出错误。
# 此外,我们还支持使用torchdistX(https://github.com/pytorch/torchdistX)的``deferred_init`` API初始化的模块。
# 在这种情况下,延迟初始化的模块将通过调用torchdistX的materialize_module或传入的param_init_fn(如果不为None)来进行默认初始化。同一个Callable被应用于初始化所有的元模块。请注意,在进行任何FSDP分片逻辑之前,将应用此初始化函数。
# device_id (Optional[Union[int, torch.device]]):
# 描述应将FSDP模块移动到的CUDA设备,确定像分片这样的初始化发生的位置。如果未指定此参数且module在CPU上,则会发出警告,提到可以为更快的初始化指定此参数。
# 如果指定了,生成的FSDP实例将驻留在此设备上,包括在需要时移动被忽略模块的参数。请注意,如果指定了device_id但module已经在不同的CUDA设备上,则会抛出错误。(默认值:None)
# sync_module_states(bool):
# 如果为True,每个单独包装的FSDP单元将从rank 0广播模块参数,以确保在初始化后它们在所有rank上保持一致。
# 这有助于确保在开始训练之前,模型参数在所有rank上是相同的,但会增加__init__的通信开销,因为每个单独包装的FSDP单元至少会触发一次广播。
# 这也可以帮助以内存高效的方式加载由state_dict获取的检查点,并由load_state_dict加载。有关此示例,请参阅:class:FullStateDictConfig的文档。(默认值:False)
# forward_prefetch(bool):
# 如果为True,则FSDP在前向传递期间显式地预取(pre train)下一个即将到来的 all-gather。
# 这可以提高CPU密集型工作负载的通信和计算重叠。这仅适用于静态图模型,因为前向顺序基于第一次迭代的执行而固定。(默认值:False)
# limit_all_gathers(bool):
# 如果为False,则FSDP允许CPU线程在没有任何额外同步(synchrnization)的情况下调度all-gather。
# 如果为True,则FSDP显式地同步CPU线程,以防止过多的即时all-gather。
# 此bool仅影响调度 all-gather的分片策略。启用此选项可以帮助降低CUDA malloc重试次数。
# ignored_parameters(Optional[Iterable[torch.nn.Parameter]]):
# 被忽略的参数将不会由此FSDP实例管理,这意味着这些参数不会被FSDP扁平化和分片,它们的梯度也不会被同步。
# 通过这个新添加的参数,ignored_modules可能很快就会被弃用。为了向后兼容,目前保留了ignored_parameters和ignored_modules两者,但是FSDP只允许其中一个被指定为非None。4.2 FlatParameter
- nn.Parameter 的子类
- 这是由FullyShardedDataParallel类使用的扁平化参数。它由一个或多个原始参数组成,这些参数被扁平化并连接起来构建扁平化参数。
- 根据当前的设计,该参数在逻辑上表示未分片和分片的扁平化参数,并且其数据可以动态更改。
- 在FullyShardedDataParallel构造函数中,该参数被初始化为未分片的,然后就地进行分片。
- 在运行时,该参数会被惰性地(重新)初始化。
- 分片参数数据保存在self._local_shard中,并创建一个新的Tensor self._full_param_padded,它是全局聚集的目标,并且在此后拥有未分片的参数存储。 (参见FlatParamHandle.init_flat_param_attributes方法。)
- 在整个运行时期间,参数数据根据需要更改存储方式,例如分片的扁平化参数、降低精度的分片化参数或未分片的扁平化参数。
class FlatParameter(nn.Parameter):
self._unpadded_unsharded_size:torch.Size # 未分片未padding的扁平化参数的size
self._padded_unsharded_size:torch.Size # 未分片但padding的扁平化的参数的size
self._sharded_size: torch.Size # 分片参数的大小,包括填充。对于“NO_SHARD”情况,它与未分片的大小相同
self._param_infos: Tuple[ParamInfo, ...] # 每个Parameters 的 info : param_name, module, module_name
self._numels: Tuple[int, ...] # 每个 parameter的元素个数
self._shapes: Tuple[torch.Size, ...] # 每个parameter的shape
self._fqns: Tuple[str, ...] # 原始参数的完全限定名称(FQN)的前缀(在所属句柄的_fully_sharded_module之前)。这些名称在以该模块为根的子树中保证是唯一的。
self._num_params:int # 被扁平化到这个FlatParameter中的原始参数数量;这是_param_infos、_numels、_shapes和_fqns的长度。
self._shared_param_infos: Tuple[SharedParamInfo, ...] # 共享参数的(非Prim的)Info:共享的参数第一次遇到设置为 prim,之后再次遇到便成为 shared parameter
self._param_extensions:Tuple[Optional[Any], ...] # 参数扩展(即一些参数级别的状态),用于自定义预扁平化和后解扁平化的行为。这是实验性的功能,用户不应该依赖它在未来的存在。
self._modules:Set[nn.Module] # 参数被扁平化的模块集合
self._shard_param_offsets:List[Tuple[int, int]) # 当前rank对每个扁平化的参数的[start, end]偏移量(以numel为单位);对于未在rank间进行分片的任何参数“p”,值为[0,p.numel()-1]。
self._shard_indices:Tuple[int, int] #
self._shard_numel_padded:int # 为此rank的分片化扁平化参数填充的元素数量。
self._local_shard:Tensor # ***重要*** # 如果使用分片策略,则为带有填充的分片化扁平化参数。如果使用“NO_SHARD”,那么这就是未填充的未分片扁平化参数。
self._full_param_padded:Tensor # 带有padding的未分片扁平化参数。对于“NO_SHARD”情况,此处未定义。当对参数使用混合精度时,此参数具有低精度。
self._full_prec_full_param_padded:Tensor # 带有padding的全精度未分片化参数。在使用混合精度时,用于计算之外的分片还原。这在“NO_SHARD”情况下永远不会定义。
self._post_backward_hook_state:Tuple[AccumulateGrad, RemovableHandle] # 扁平化参数的AccumulateGrad对象和后向传播钩子处理句柄.
self._mp_shard:Tensor # 低精度的分片化Flattened Parameter,带有填充。只有在启用参数混合精度时才定义。“NO_SHARD” 时,此用此Tensor计算。
self._cpu_grad:Tensor # 存储在CPU上的带padding的 sharded grad。只有在启用参数offload时才定义。
self._saved_grad_shard:Tensor # 先前迭代的用于梯度累积的带填充的分片化梯度,不使用no_sync方法。
self._params: Optional[List[nn.Parameter]] # 如果use_orig_params=True,则为原始参数变量,否则为None。
self._shared_params:Optional[List[nn.Parameter]] # 如果use_orig_params=True,则为原始共享参数变量,否则为None。
self._tensors:Optional[List[Optional[Tensor]]] # 这样可以在use_orig_params=True时保存在前向传播中创建的Tensor视图,并由autograd跟踪,否则为None。
self._is_grad_none:Optional[List[bool]] # 如果use_orig_params=True,则为原始参数梯度上的掩码,指示它是否逻辑上为None,否则为None。4.3 FlatParamHandle
- 此句柄管理扁平化参数(:class:FlatParameter)。这包括分片和视图管理。
class FlatParamHandle:
def __init__(
self,
params: Sequence[nn.Parameter],
fully_sharded_module: nn.Module,
device: torch.device,
sharding_strategy: HandleShardingStrategy,
offload_params: bool,
mp_param_dtype: Optional[torch.dtype],
mp_reduce_dtype: Optional[torch.dtype],
keep_low_precision_grads: bool,
process_group: dist.ProcessGroup,
use_orig_params: bool,
):
super().__init__()
debugpy.breakpoint()
self.device = device
self.process_group = process_group
self.rank = process_group.rank()
self.world_size = process_group.size()
self._sharding_strategy = sharding_strategy
self._offload_params = offload_params
self._use_orig_params = use_orig_params
self._keep_low_precision_grads = keep_low_precision_grads
self._training_state = HandleTrainingState.IDLE
self._debug_level = dist.get_debug_level()
self._fully_sharded_module = fully_sharded_module
self._init_flat_param(params, fully_sharded_module, use_orig_params)
self._orig_param_dtype = self.flat_param.dtype
self._use_unsharded_views(as_params=False)
self._init_param_reduce_dtypes(mp_param_dtype, mp_reduce_dtype)4.4 init 时关键节点
参数cpu --> gpu
FullyShardedDataParallel.init --> _init_param_handle_from_module --> _move_module_to_device --> module = module.to(device_from_device_id)Param gpu --> gpus FullyShardedDataParallel.init --> _init_param_handle_from_module --> _sync_module_params_and_buffers --> _sync_params_and_buffers --> dist._broadcast_coalesced
Param Flatten FullyShardedDataParallel.init --> _init_param_handle_from_module --> _init_param_handle_from_params --> FlatParamHandle.init --> FlatParamHandle._init_flat_param --> flatten_params --> flat_param_data = torch.cat(flat_params, dim=0) (是将一个module 中所有 parameter 拼成一个一维 Tensor)
Param sharded FullyShardedDataParallel.init --> _init_param_handle_from_module --> _init_param_handle_from_params --> FlatParamHandle.init && sharded --> FlatParamHandle._get_shard --> _get_unpadded_shard --> chunks = torch.flatten(tensor).chunk(world_size) && chunk = chunks[rank] (参数拆分)
4.5 runtime 时关键节点
_pre_forward_unshard
- FullyShardedDataParallel--> forward() --> _pre_forward --> unshard_fn(_pre_forward_unshard) --> _unshard --> FlatParamHandle.unshard --> _all_gather_flat_param --> dist.all_gather_into_tensor
_post_backward_hook
注册post-backward 钩子来重新对Param 切片 同时 reduce-scatter 他们的梯度。每次前向传播都要重新注册以防止grad_fn 变化。
- FullyShardedDataParallel--> forward() --> _pre_forward --> _register_post_backward_hooks --> _post_backward_hook --> _reshard --> FlatParamHandle.reshard --> flat_param.data = flat_param._local_shard && _free_storage(unsharded_flat_param)
_post_forward_reshard
- FullyShardedDataParallel--> forward() --> _post_forward --> reshard_fn(_post_forward_reshard) --> _reshard --> FlatParamHandle.post_reshard() --> _free_storage(self.flat_param._mp_shard)
_pre_backward_hook
- FullyShardedDataParallel--> forward() --> _post_forward --> _register_pre_backward_hooks --> t.register_hook(_pre_backward_hook) --> _unshard