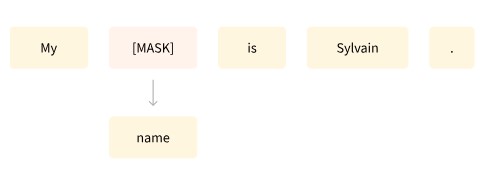
1 模型跑通
git clone https://github.com/huggingface/transformers.git
export PYTHONPATH=*/transformers/src:$PYTHONPATH
cd transformers
git checkout v4.31.0
cd */transformsers/examples/pytorch/question-answering
python run_seq2seq_qa.py \
--model_name_or_path t5-small \
--dataset_name squad_v2 \
--context_column context \
--question_column question \
--answer_column answers \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_seq2seq_squad/2 t5 介绍
3 position embedding 总结
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:
- 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;
- 想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
3.1 绝对位置编码
一般来说,绝对位置编码会加到输入中:在输入的第 k 个向量 中加入位置向量 变为 ,其中 只依赖于位置编号k.
- 绝对位置编码公式表达如下:

3.1.1 三角函数式(Sinusoidal)位置编码
三角函数式(Sinusoidal)位置编码是在原 Transformer论文 中使用的一种显式编码。
其中 分别是位置 k 的编码向量的第 个分量, d 是位置向量的维度。
固定维度d为500,绘制不同N下的position embedding,具体如下:
- 示例:
可以看到随着N的增大,周期会明显变长。文章中的N为10000,作者没有具体的解释,猜测可能是为了能让周期是一个很大的数,更好的区分开每个位置。
3.1.2 可学习(Learnable)的位置编码
很显然,绝对位置编码的一个最朴素方案是不特意去设计什么,而是直接将位置编码当作可训练参数,比如最大长度为512,编码维度为768,那么就初始化一个512×768的矩阵作为位置向量,让它随着训练过程更新。现在的BERT、GPT等模型所用的就是这种位置编码.
对于这种训练式的绝对位置编码,一般的认为它的缺点是没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调。
风极一时的 bert 中采用的就是这种编码方式,如下图所示:
3.2 相对位置编码
相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与被Attention的位置的相对距离,由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现。对于相对位置编码来说,它的灵活性更大,更加体现出了研究人员的“天马行空”。
3.2.1 经典的相对位置编码
相对位置编码起源于Google的论文《Self-Attention with Relative Position Representations》,一般认为,相对位置编码是由绝对位置编码启发而来,我们再回忆下一般的带绝对位置编码的Attention:
其中 softmax 对 j 那一维归一化,这里的向量都是指行向量。我们初步展开 .
为了引入相对位置信息,Google把第一项位置去掉,第二项 改为二元位置向量 . 变成:
以及 中的 换成 :
所谓相对位置,是将本来依赖于二元坐标 (i, j) 的向量 ,改为只依赖于相对距离 i-j,并且通常来说会进行截断,以适应不同任意的距离:
这样一来,只需要有限个位置编码,就可以表达出任意长度的相对位置(因为进行了截断),不管 是选择可训练式的还是三角函数式的,都可以达到处理任意长度文本的需求。
3.2.2 T5 中的相对位置编码
T5模型出自文章《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》,里边用到了一种更简单的相对位置编码。
将 完全展开得到:
上式每一项可以分别理解为“输入-输入”、“输入-位置”、“位置-输入”、“位置-位置”四项注意力的组合。如果我们认为输入信息与位置信息应该是独立(解耦)的,那么它们就不应该有过多的交互,所以“输入-位置”、“位置-输入”两项Attention可以删掉, 实际上只是一个只依赖于(i,j) 的标量,我们可以直接将它作为参数训练出来,即简化为:
简而言之,它仅仅是在Attention矩阵的基础上加一个可训练的偏置项而已.
比较“别致”的是,不同于常规位置编码对将 视为 i-j 的函数并进行截断的做法, T5 对相对位置进行了一个“分桶”处理,即相对位置是 i-j 的位置实际上对应的是 f(i-j) 位置,映射关系如下:
具体的映射代码,读者自行看源码就好。这个设计的思路其实也很直观,就是比较邻近的位置(0~7),我们需要比较得精细一些,所以给它们都分配一个独立的位置编码,至于稍远的位置(比如8~11),我们不用区分得太清楚,所以它们可以共用一个位置编码,距离越远,共用的范围就可以越大,直到达到指定范围再clip。
3.3 旋转位置编码
旋转位置编码(Rotary Position Embedding,RoPE)是论文 Roformer: Enhanced Transformer With Rotray Position Embedding 提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。而目前很火的 LLaMA、GLM 模型也是采用该位置编码方式。和相对位置编码相比,RoPE 具有更好的外推性,目前是大模型相对位置编码中应用最广的方式之一。
思考:什么是大模型外推性?
外推性是指大模型在训练时和预测时的输入长度不一致,导致模型的泛化能力下降的问题。例如,如果一个模型在训练时只使用了 512 个 token 的文本,那么在预测时如果输入超过 512 个 token,模型可能无法正确处理。这就限制了大模型在处理长文本或多轮对话等任务时的效果。
3.3.1 RoPE 原理
RoPE 论文中指出,为了能利用上token的相对位置信息,假定 query 向量 和 key 向量 之间的内积操作可以被一个函数 g 表示,该函数 g 的输入是词嵌入向量 , 和它们之间的相对位置 m - n:
接下来的目标就是找到一个等价的位置编码方式,从而使得上述关系成立。假定现在词嵌入向量的维度是两维,这样就可以利用 2 维度平面上的向量的几何性质,然后论文中提出了一个满足上述关系的 f 和 g 的形式如下:
这里面 Re 表示复数的实部。
进一步地, 可以表示成下面的式子:
同理, 表示成下面的式子:
看到这里会发现,这不就是向量乘以了一个旋转矩阵吗?这就是为什么叫做旋转位置编码的原因。
最终 可以表示如下:
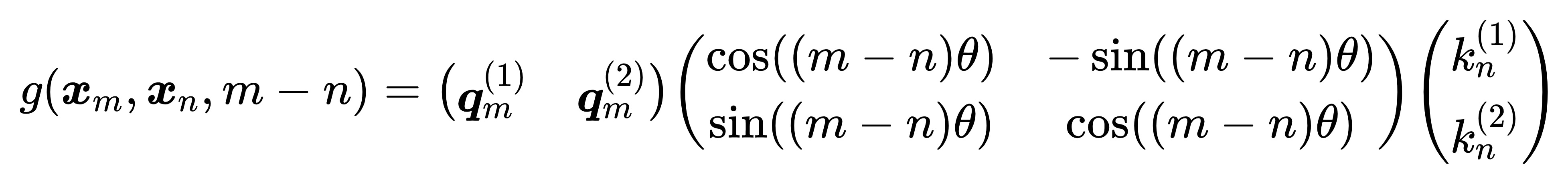
3.3.2 2 维扩展到多维
实际中 embedding 维度 都是多维的,将2维推广到任意维度,可以表示如下:
内积满足线性叠加性,因此任意偶数维的 RoPE,我们都可以表示为二维情形的拼接,即
- 其中
将 RoPE 应用到前面公式 g 的 Self-Attention 计算,可以得到包含相对位置信息的 Self-Attetion:
值得指出的是,由于 是一个正交矩阵,它不会改变向量的模长,因此通常来说它不会改变原模型的稳定性。
3.3.3 RoPE 的高效计算
由于 的稀疏性,所以直接用矩阵乘法来实现会很浪费算力,推荐通过下述方式来实现 RoPE:
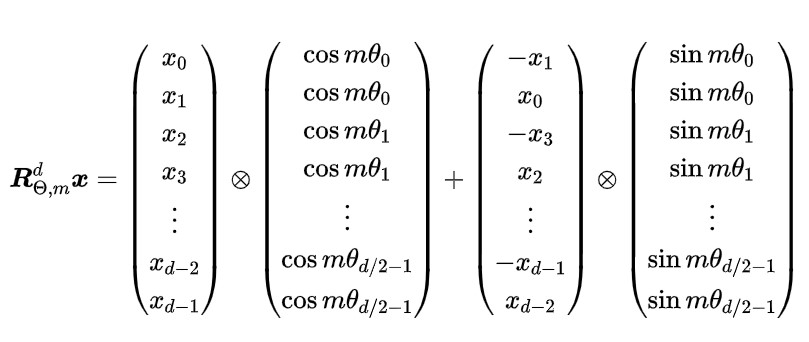
其中, 逐位对应相乘,即计算框架中的 运算。从这个实现也可以看到,RoPE 可以视为是乘性位置编码的变体。总结来说,RoPE 的 self-attention 操作的流程是:对于 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量,然后对每个 token 位置都计算对应的旋转位置编码,接着对每个 token 位置的 query 和 key 向量的元素按照两两一组应用旋转变换,最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果。具体过程可展示如下:
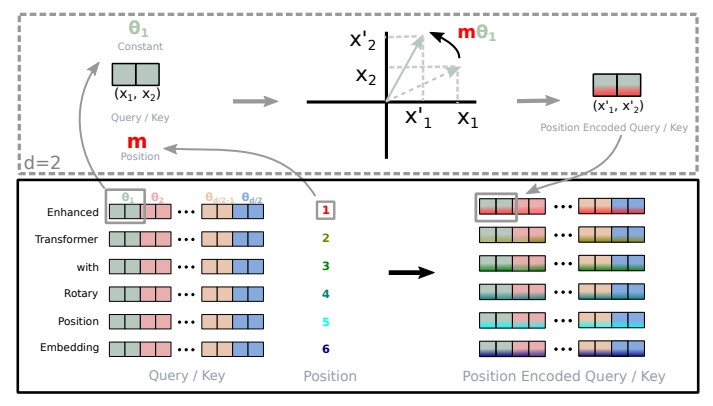
可以看到,RoPE 形式上和前面公式 Sinusoidal 位置编码有点相似,只不过 Sinusoidal 位置编码是加性的,而 RoPE 可以视为乘性的。在 的选择上,RoPE 同样沿用了 Sinusoidal 位置编码的方案,即
(d 就是 dimension) ,它可以带来一定的远程衰减性。
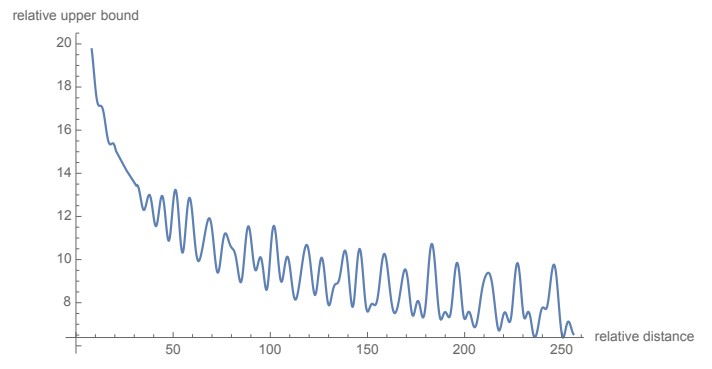
从图中我们可以看到随着相对距离的变大,内积结果有衰减趋势的出现。因此,选择 ,确实能带来一定的远程衰减性。论文中还试过以 为初始化,将 视为可训练参数,然后训练一段时间后发现 并没有显著更新,因此干脆就直接固定 了。
3.3.4 llama 中的RoPE 代码实现
# 生成旋转矩阵
def precompute_freqs_cis(dim: int, seq_len: int, theta: float = 10000.0):
# 计算词向量元素两两分组之后,每组元素对应的旋转角度\theta_i
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# 生成 token 序列索引 t = [0, 1,..., seq_len-1]
t = torch.arange(seq_len, device=freqs.device)
# freqs.shape = [seq_len, dim // 2]
freqs = torch.outer(t, freqs).float() # 计算m * \theta
# 计算结果是个复数向量
# 假设 freqs = [x, y]
# 则 freqs_cis = [cos(x) + sin(x)i, cos(y) + sin(y)i]
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
return freqs_cis
# 旋转位置编码计算
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
# xq.shape = [batch_size, seq_len, dim]
# xq_.shape = [batch_size, seq_len, dim // 2, 2]
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 2)
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 2)
# 转为复数域
xq_ = torch.view_as_complex(xq_)
xk_ = torch.view_as_complex(xk_)
# 应用旋转操作,然后将结果转回实数域
# xq_out.shape = [batch_size, seq_len, dim]
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(2)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(2)
return xq_out.type_as(xq), xk_out.type_as(xk)
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.wq = Linear(...)
self.wk = Linear(...)
self.wv = Linear(...)
self.freqs_cis = precompute_freqs_cis(dim, max_seq_len * 2)
def forward(self, x: torch.Tensor):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(batch_size, seq_len, dim)
xk = xk.view(batch_size, seq_len, dim)
xv = xv.view(batch_size, seq_len, dim)
# attention 操作之前,应用旋转位置编码
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# scores.shape = (bs, seqlen, seqlen)
scores = torch.matmul(xq, xk.transpose(1, 2)) / math.sqrt(dim)
scores = F.softmax(scores.float(), dim=-1)
output = torch.matmul(scores, xv) # (batch_size, seq_len, dim)
# ......