1 代码介绍
2 代码复现步骤
git clone https://github.com/huggingface/diffusers.git3 stable diffusion 整体结构
3.1 整体流程图
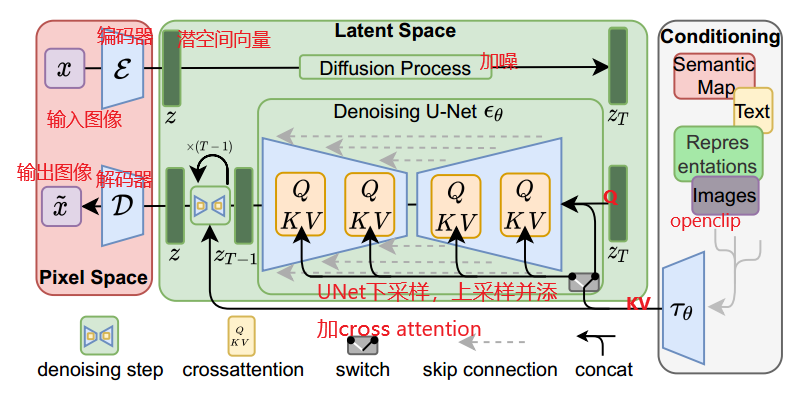
3.2 sd 训练流程图
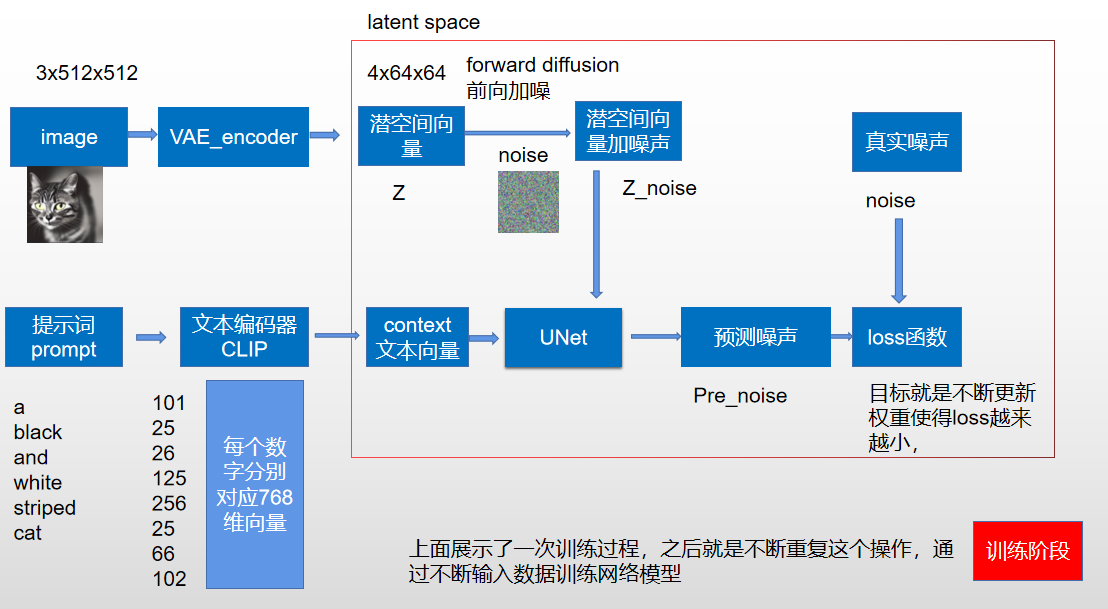
注意:训练时噪音的严重程度是和时间步有关的,加噪过程是按照noisy 和 orig_imag 加权平均得到的,时间步越小加的噪音越小
- 具体的加噪过程如下:
def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
timesteps: torch.IntTensor,
) -> torch.FloatTensor:
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device, dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
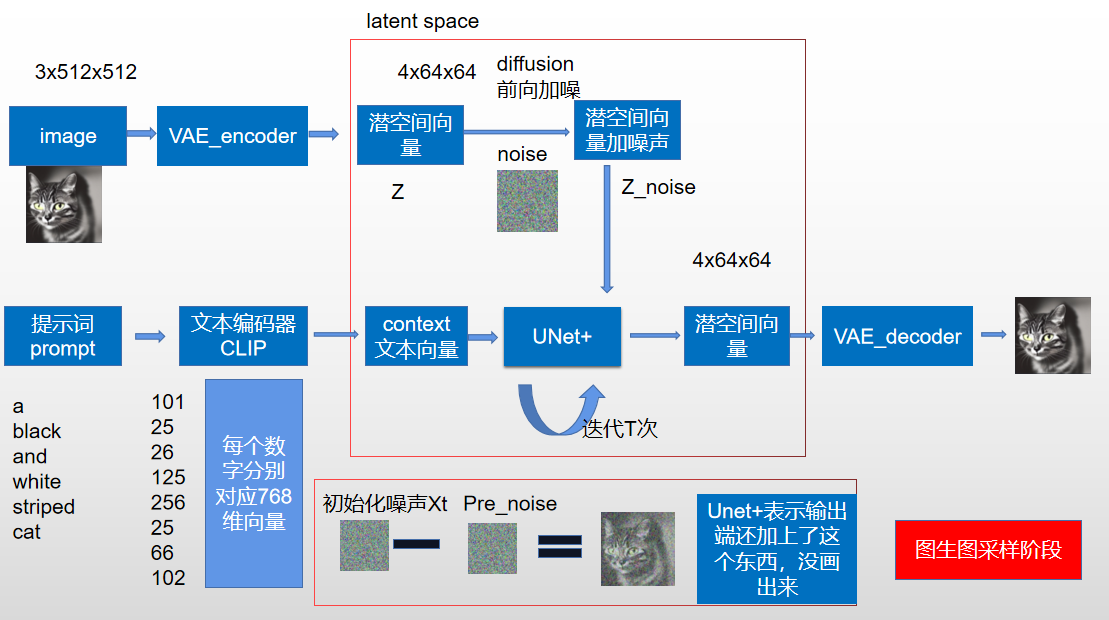
return noisy_samples3.3 sd 推理流程图
3.4 clip 原理图
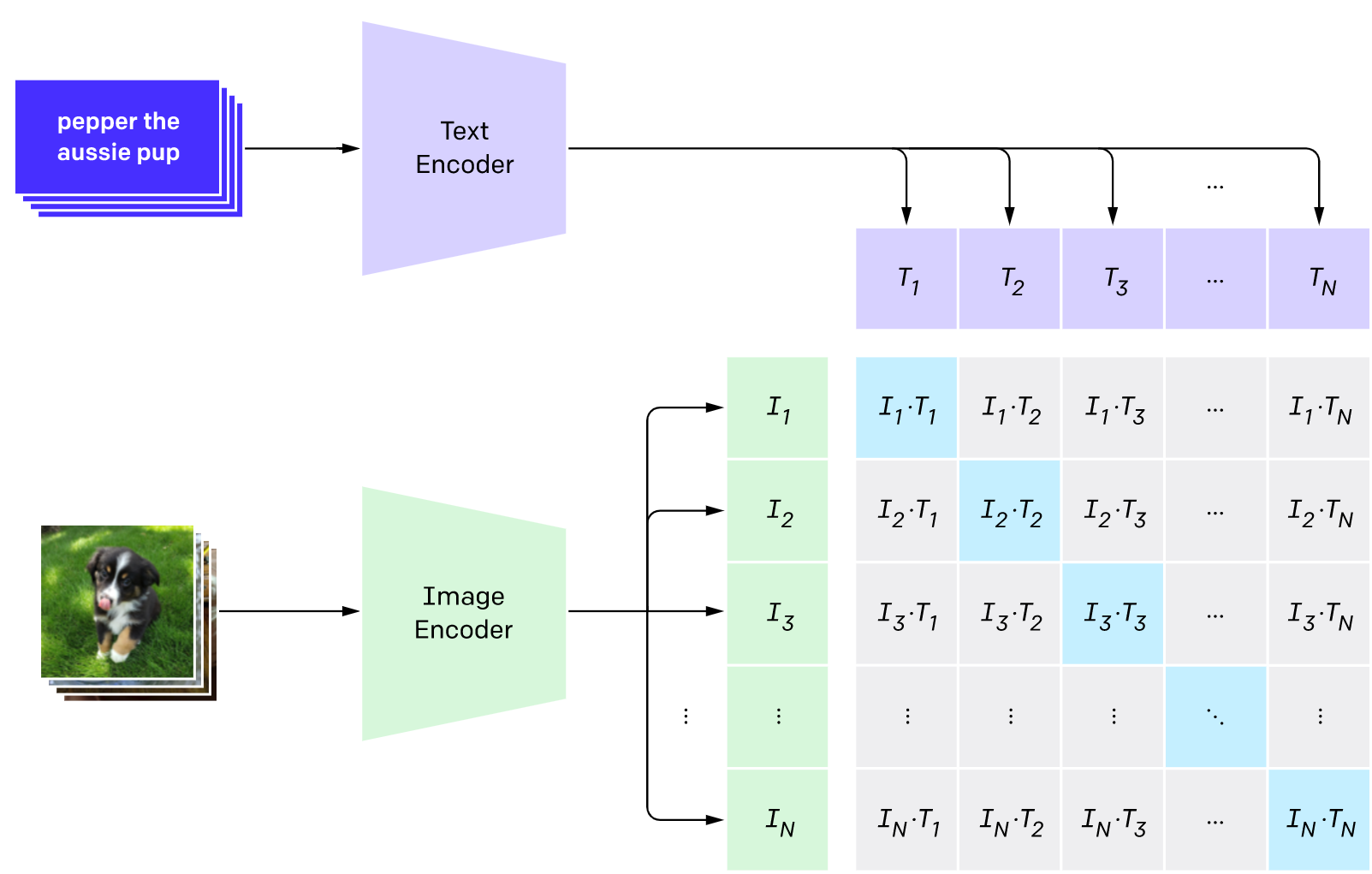
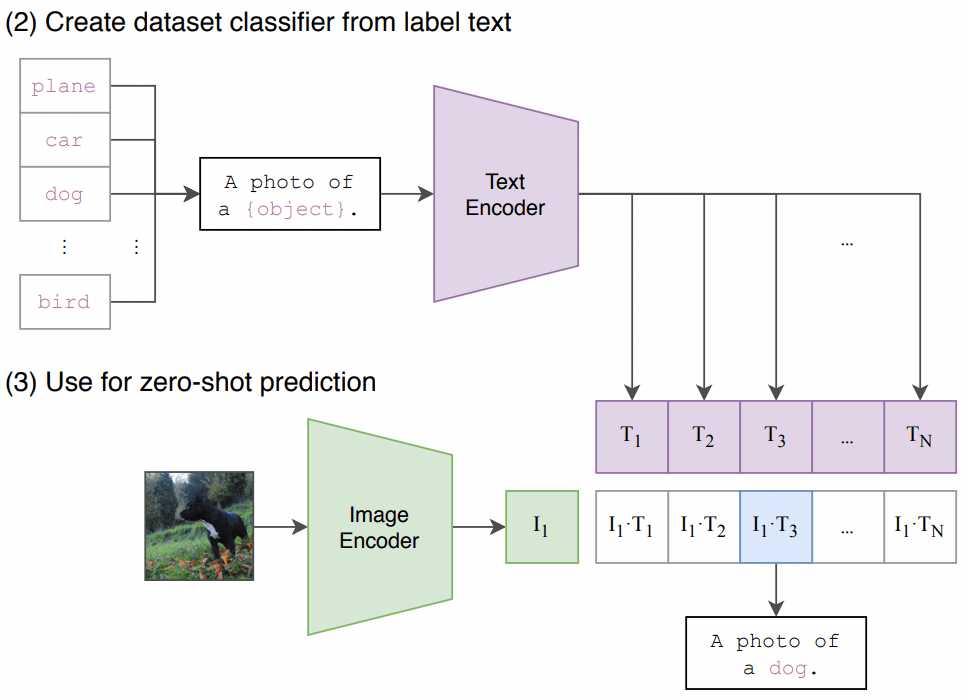
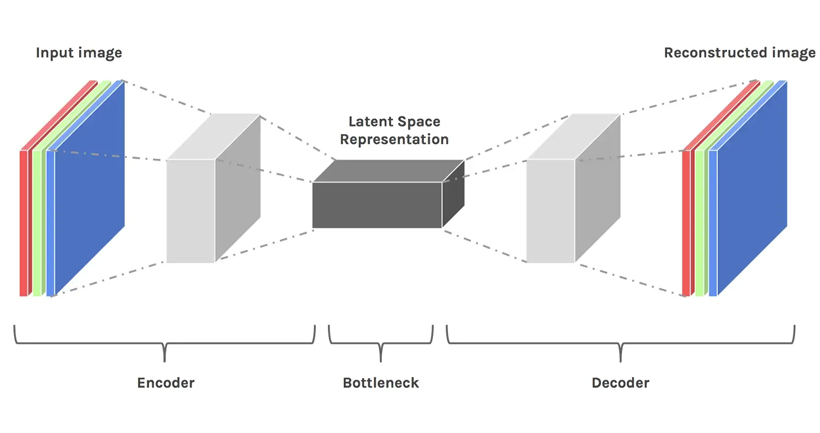
3.5 latent space
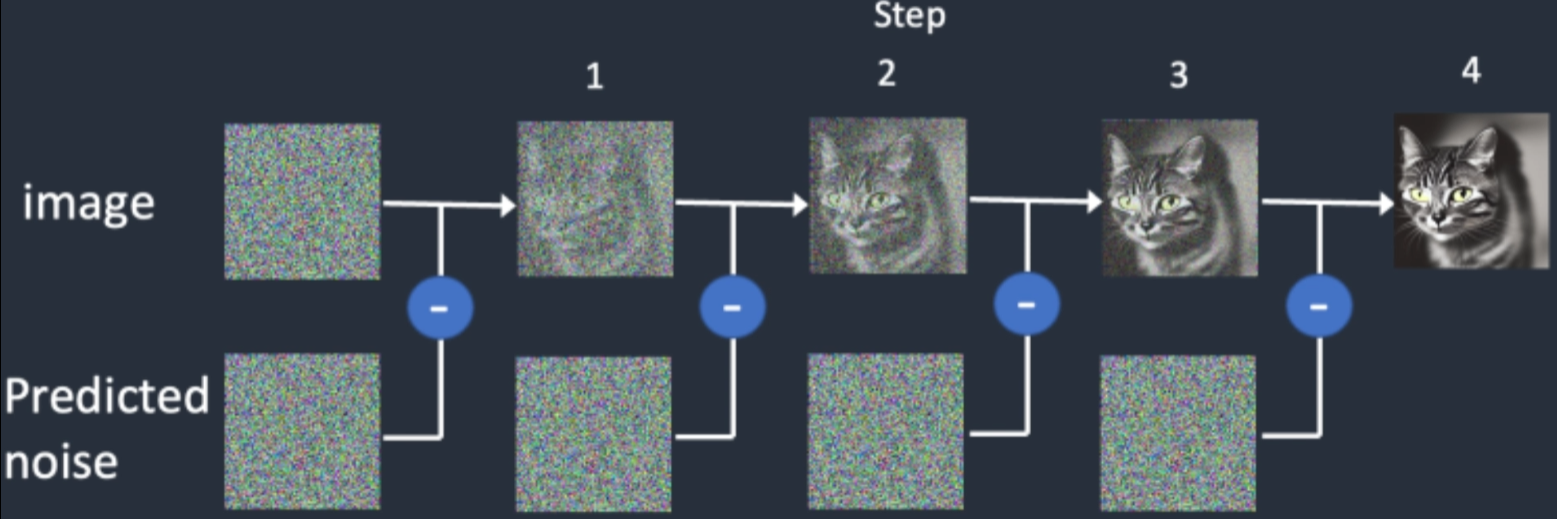
3.6 noiser and denoiser

4 stable diffusion 具体模型结构
4.1 clip 结构
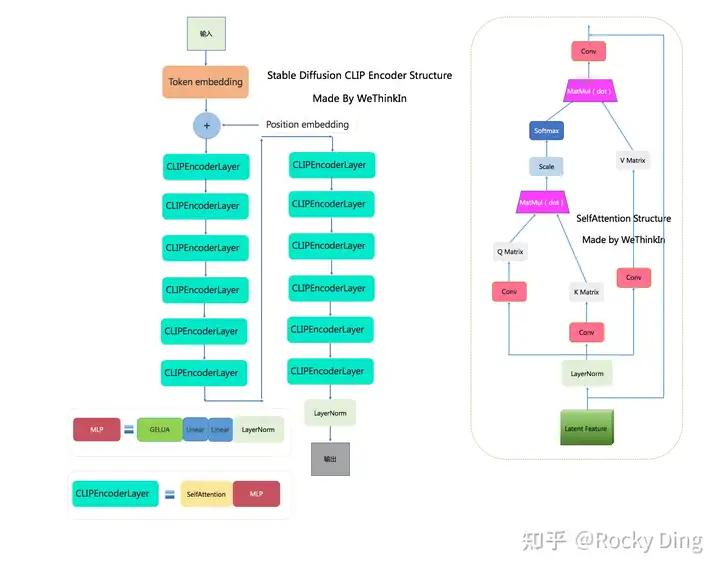
4.2 vae 模型结构
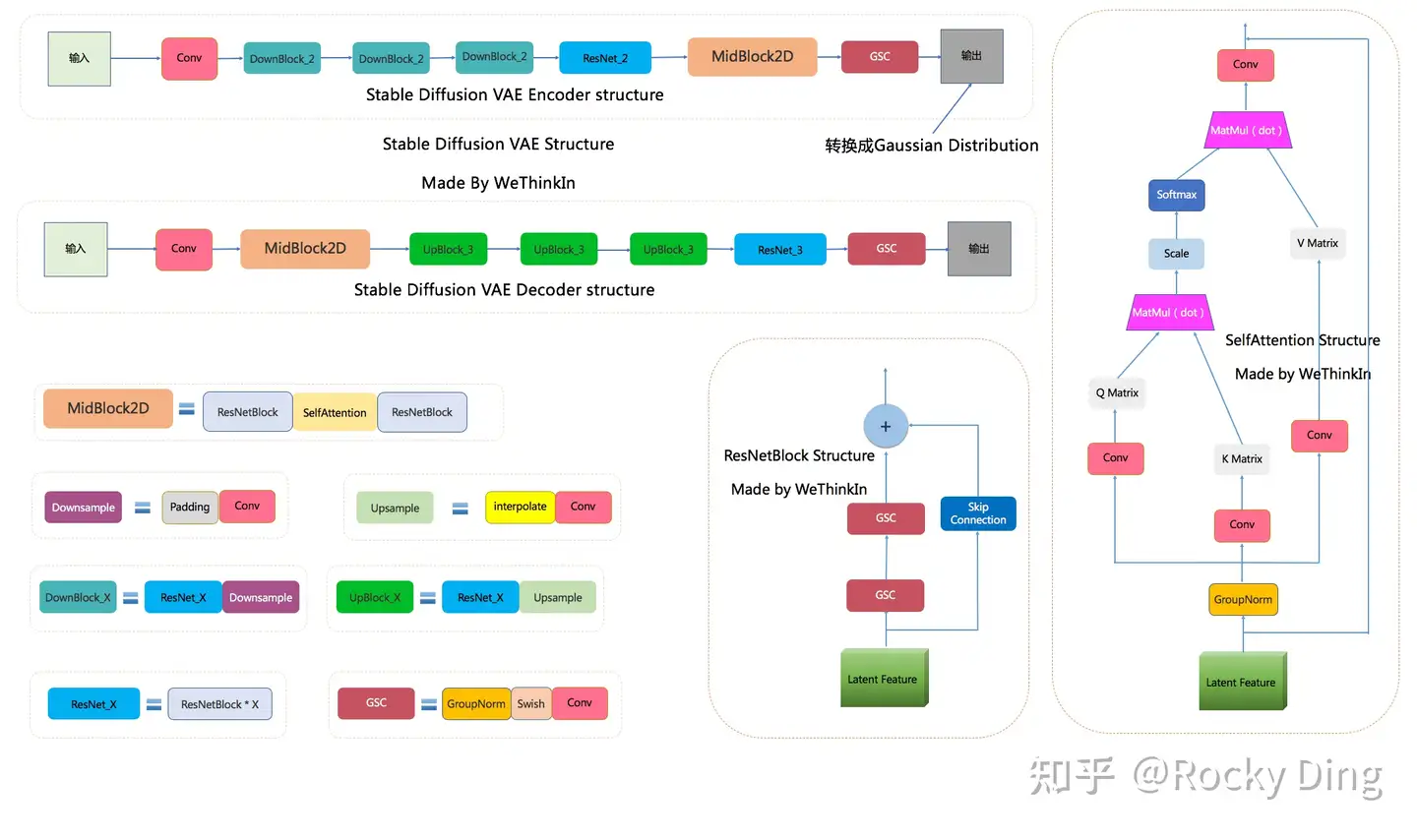
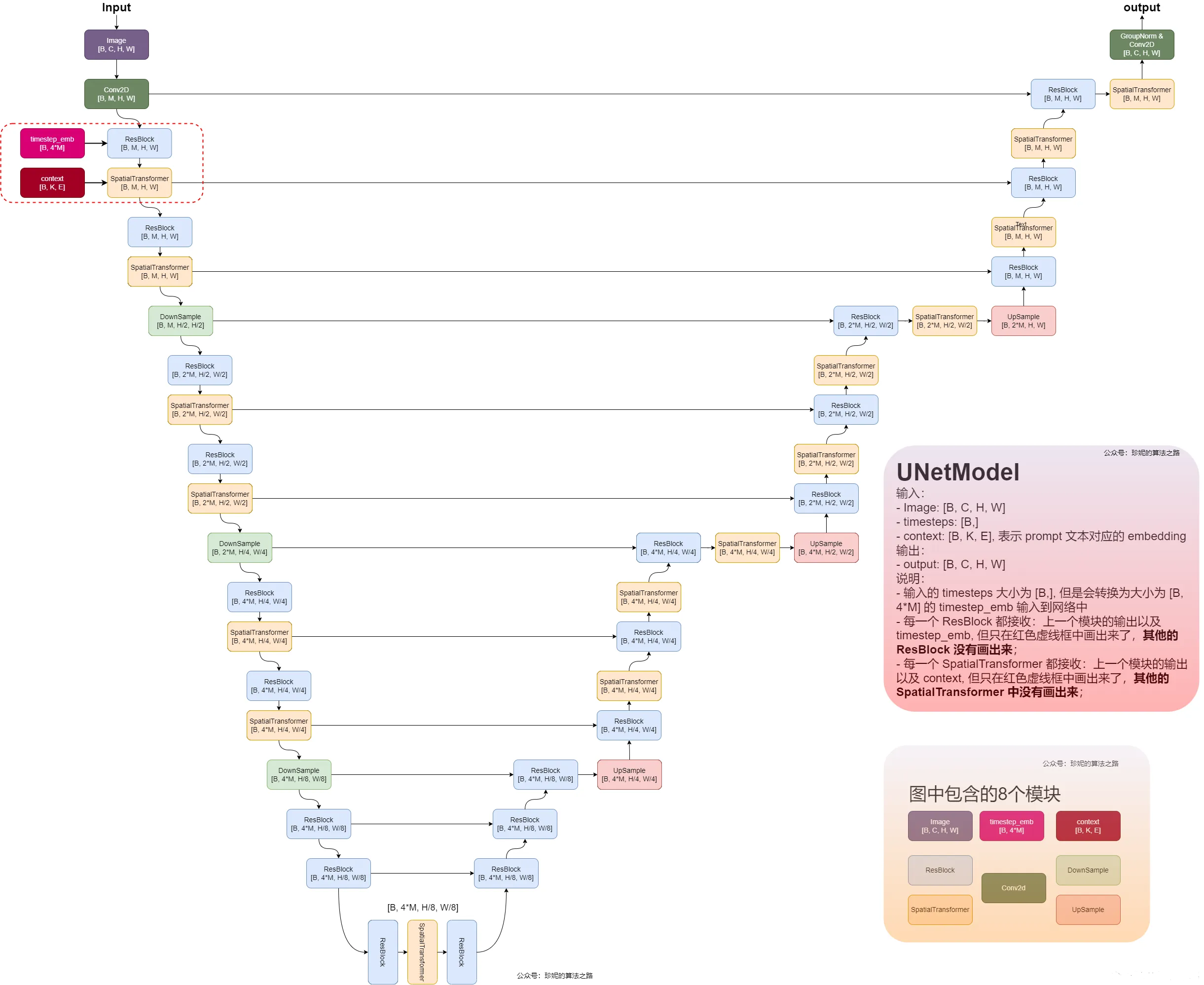
4.2 unet-base 模型结构图
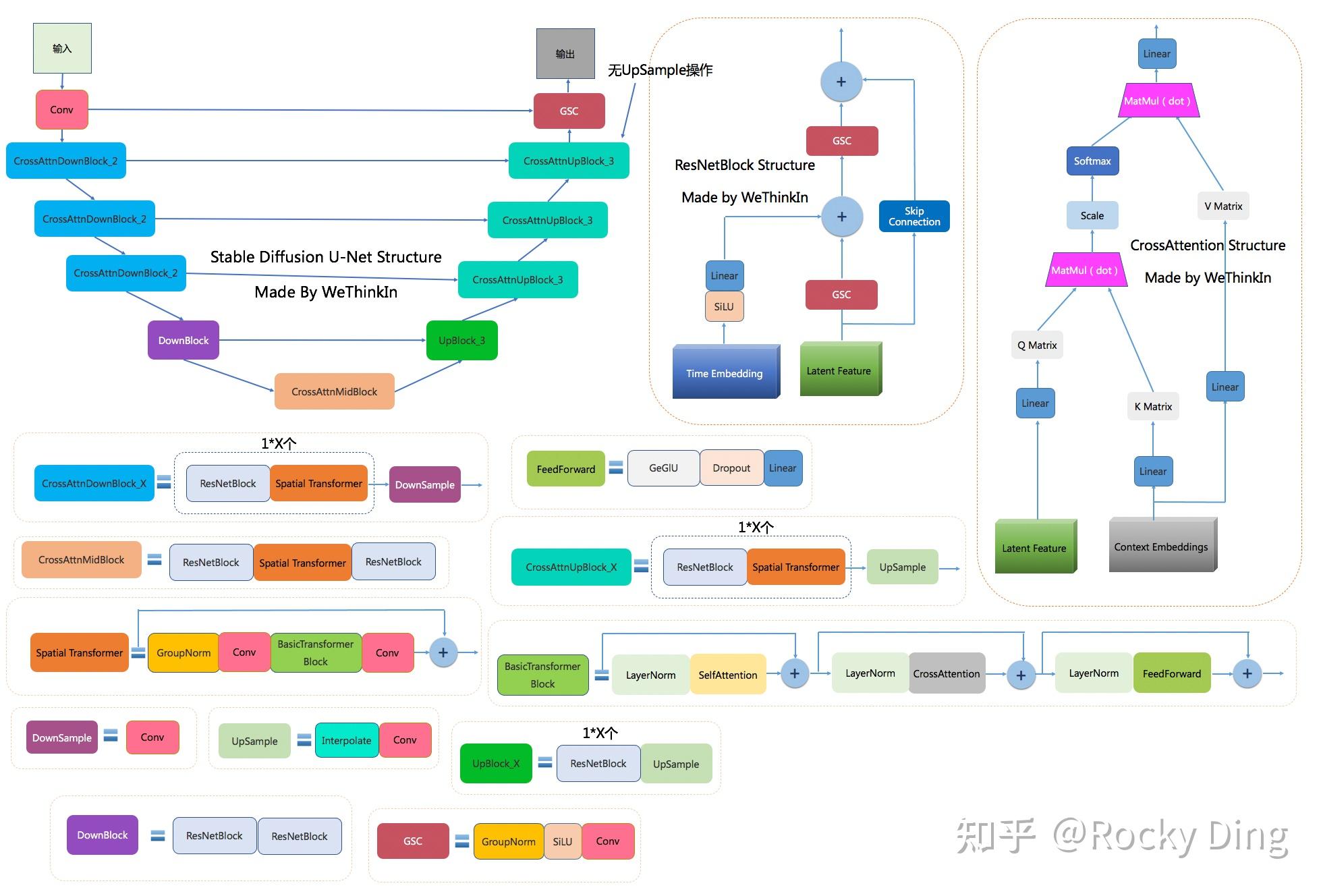
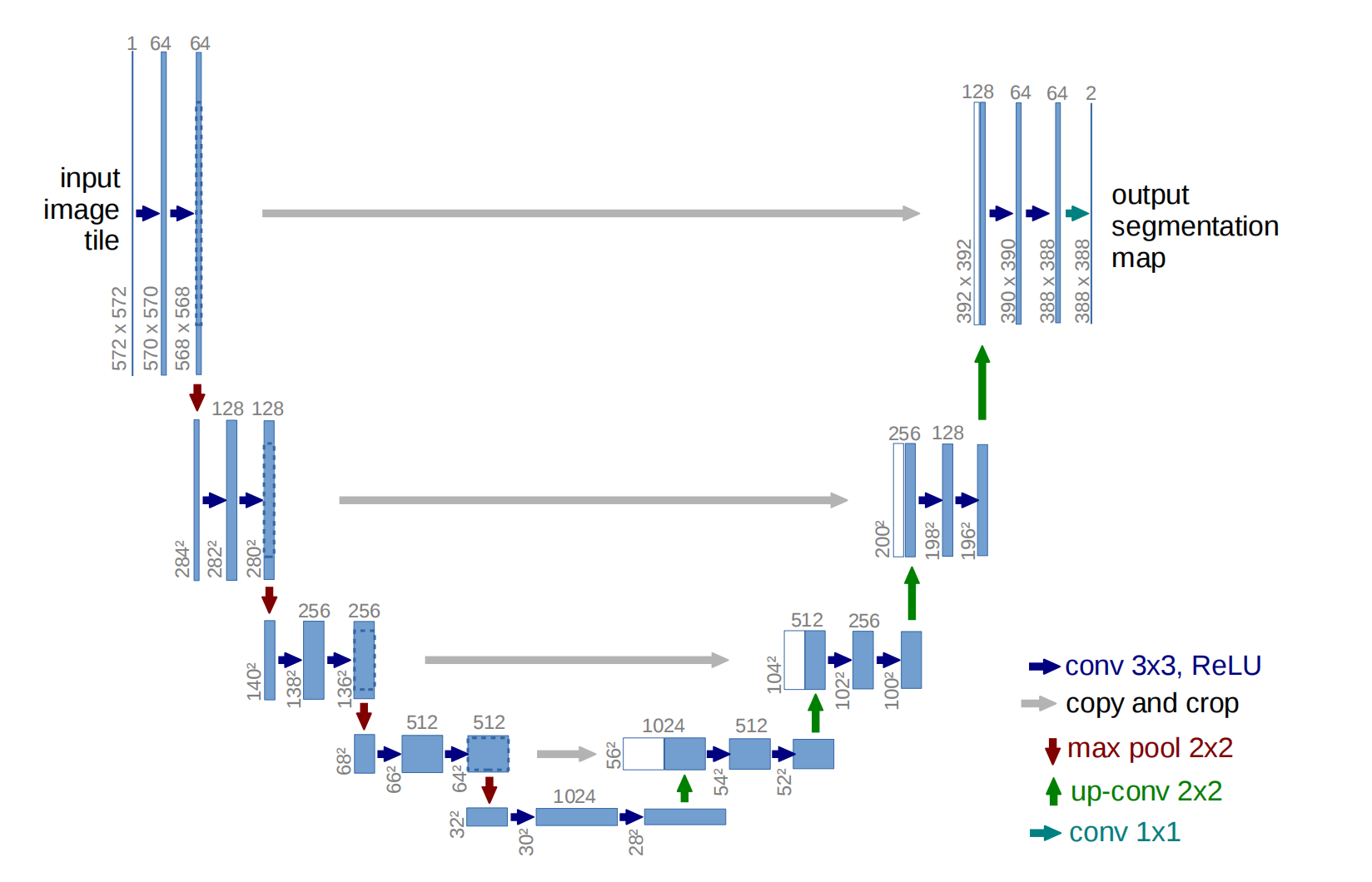
5 评价指标
5.1 clip score
Clip score是指将文本和图像对输入到OpenAI的CLIP(Contrastive Language-Image Pre-training)模型后分别转换为特征向量,然后计算它们之间的余弦相似度。当CLIP Score较高时,图像-文本对之间的相关性更高。CLIP Score评估自然语言(Promote 文本)和图像对之间的匹配度和相关性。值越大(接近1),评估越高。
,
5.2 FID
FID(Fréchet Inception Distance) score 是一种用于评估生成图像质量的度量标准,专门用于评估模型生成图片的性能,FID可以衡量生成图像的逼真度(image fidelity), 计算公式如下所示:
其中, p 表示真实图像的分布, q 表示生成图像的分布, 和 分别表示两个分布的特征向量的均值, 和 分别表示两个分布的特征向量的协方差矩阵。Tr 表示矩阵的迹运算, 表示欧几里得范数。
具体来说, FID首先用 Inception network提取真实数据和生成数据的特征向量, 然后计算这两个特征向量集合的均值 , 和协方差矩阵 , 。最后计算上述公式得到 FID值。
FID 值越低代表两个分布越相似,生成的数据与真实数据分布越相似。
6 sd 进阶
6.1 sd2 之前版本异同
- SD v1.1:在laion2B-en数据集上以256x256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
- SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
- SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
- SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
- SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
- SD 2.0:采用了更大的text encoder:基于OpenCLIP在laion-2b数据集上训练的CLIP ViT-H/14模型,其参数量为354.03M,相比原来的text encoder(CLIP ViT-L/14)模型大了约3倍.
- SD 2.0 UNet: 相比SD 1.x几乎没有改变,就是由于换了CLIP模型,cross attention dimension从原来的768变成了1024, 不同stage的attention模块是固定attention head dim为64;
- SD 2.0 : 除了512x512版本的模型,还包括768x768版本的模型;
- SD 2.0 768x768 模型 : 在512x512模型基础上用图像分辨率大于768x768的子集继续训练, 优化目标不再是noise_prediction,而是采用v-objective
- SD 2.1 : SD 2.1是在SD 2.0的基础上放开了限制(降低审查标准punsafe=0.98) 继续finetune,所以增强了人像的生成效果。
- SD unCLIP : 是在原来的SD模型的基础上增加了CLIP的image encoder的nosiy image embeddings作为condition。
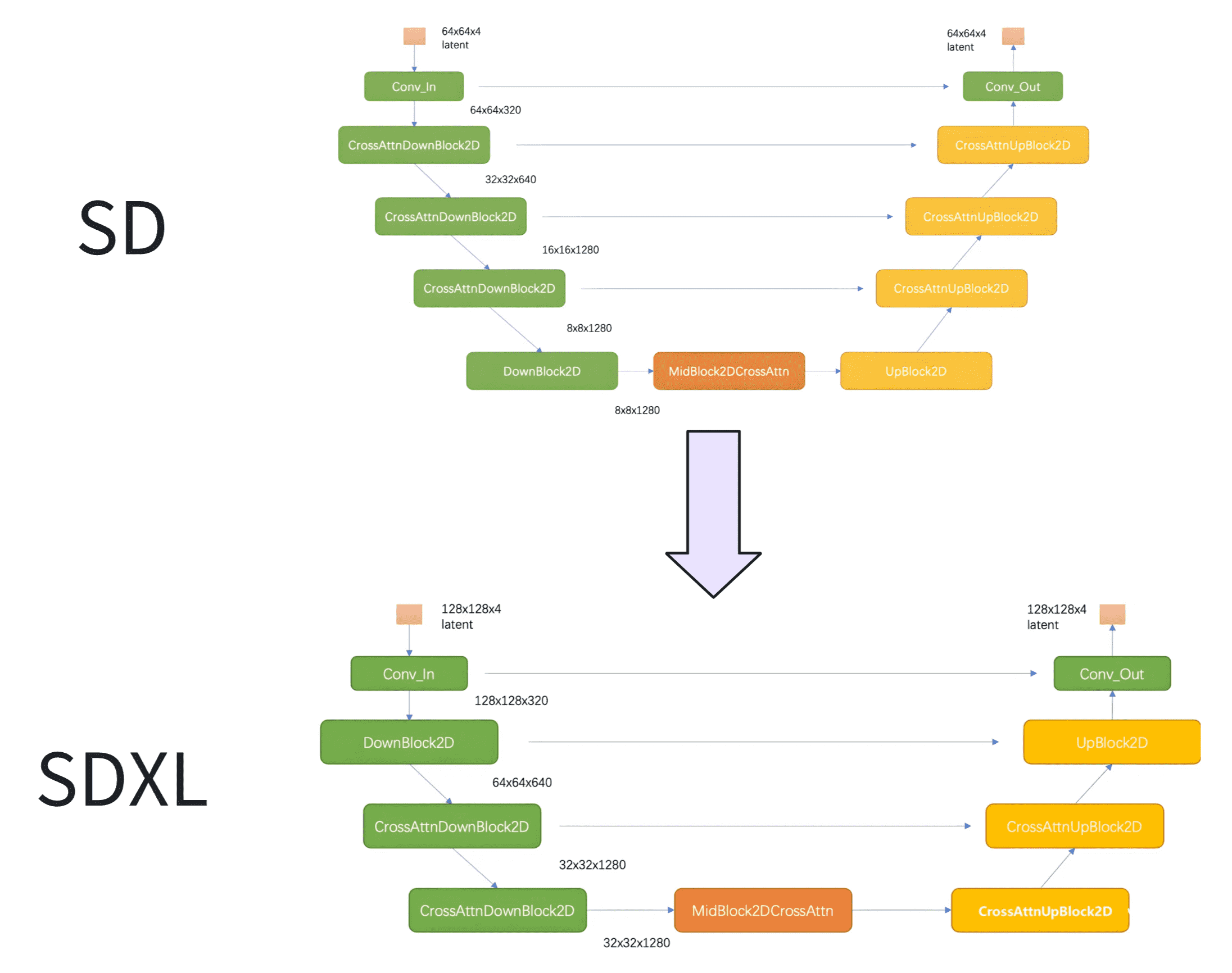
6.2 从 SD 到 SDXL
SDXL 的第一个 stage 采用的是普通的 DownBlock,而不是基于 attention 的 CrossAttnDownBlock。此外,SDXL 只用了 3 个 stage,只进行了两次 2x 下采样,而之前的 SD 使用 4 个 stage,包含 3 个 2x 下采样。
SDXL 中 stage2 和 stage3 的两个 CrossAttnDownBlock 中的 transformer block 数量分别为 2 和 10,并且中间的 CrossAttnMidBlock 的 transformer blocks 数量也为 10。