01-Transformer的由来
1. 引入
Transformer本身还是seq2seq结构的一个模型架构,但像RNN这样的网络他有很多问题点,每一次的预测输出是建立在上一次的输出基础上的,也算是早起自回归模型的问题点:
- 串行运行,很难以并行化的方式开展训练、提升效率。
- 只有时刻的信息,容易丢失信息
- "一步错,步步错"
- 梯度消失问题
- 输入输出序列等长限制(n2n)
由此,研究者们就在此基础上设计出了一种"优化版的Encoder 2 Decoder"的架构,其中的过渡就是Context Vector (用C表示),输入句子每个时间步的信息都包含在了这个上下文中。简单理解可以认为Encoder进行特征提取得到输入信息对应的Context Vector,然后Decoder进行解码:
- 在每个时刻,解码器都是自回归的,即上一个时刻的输出(产生的token y_{t−1})作为下当前时刻的输入之一,生成当前时刻的token 。
- 解码器最初的输入是中间语义上下文向量C,解码器依据C计算出第一个输出词和新的隐状态,即解码器的每个预测都受到先前输出词和隐状态的微妙影响。
- 解码器接着用新的隐状态和第一个输出词作为联合输入来计算第二个输出词,以此类推,直到解码器产生一个 EOS(End Of Service/序列结束)标记或者达到预定序列长度的边界。
从宏观角度看,序列建模的核心就是研究如何把长序列的上下文压缩到一个较小的状态中(好好领悟这句话)。
咋压缩呢?早期的有马尔可夫假设,也就是近因效应,如果考虑前面n个单词,这就得到了N-gram模型,即当前单词的概率取决于前n个单词。
2. Attention机制
这个在transformer之前就有了,它其实有一定的实际意义,有三种主流禅诗:
- 注意力机制的本质是上下文决定一切。
- 注意力机制是一种资源分配方案。
- 注意力机制是信息交换,或者说是是“全局信息查询”。
其实,论文“Recurrent Models of Visual Attention”中有一段话就深刻的印证了资源分配这个角度。具体如下:人类感知的一个重要特性是,人们不会一次处理整个场景。相反,人类有选择地将注意力集中在视觉空间的某些部分上,以在需要的时间和地点获取信息,并随着时间的推移将不同注视点的信息结合起来,建立场景的内部表示,指导未来的眼球运动和决策。将计算资源集中在场景的各个部分可以节省“带宽”,因为需要处理的“像素”更少。但它也大大降低了任务的复杂性,因为感兴趣的对象可以放置在注视的中心,而注视区域外的视觉环境的无关特征(“杂乱”)自然会被忽略。
所以,核心就是分配不同的权重,那又引出问题:
- 在哪里做注意力计算?
- 如何做注意力计算?
3. Q K V的引入
注意力模型的内部流程如下图所示,该模型的目标是生成V中向量的加权平均值,具体计算流程如下。
标号1是输入(两个输入),从输入生成的特征向量F会进一步生成键矩阵K和值矩阵V。
标号2使用矩阵K和查询向量q作为输入,通过相似度计算函数来计算注意力得分向量e。q表示对信息的请求,表示矩阵K的第l列对于q的重要性。
标号3通过对齐层(比如softmax函数)进一步处理注意力分数,进而得到注意力权重a。
标号4利用注意力权重a和矩阵V进行计算,得到上下文向量c。
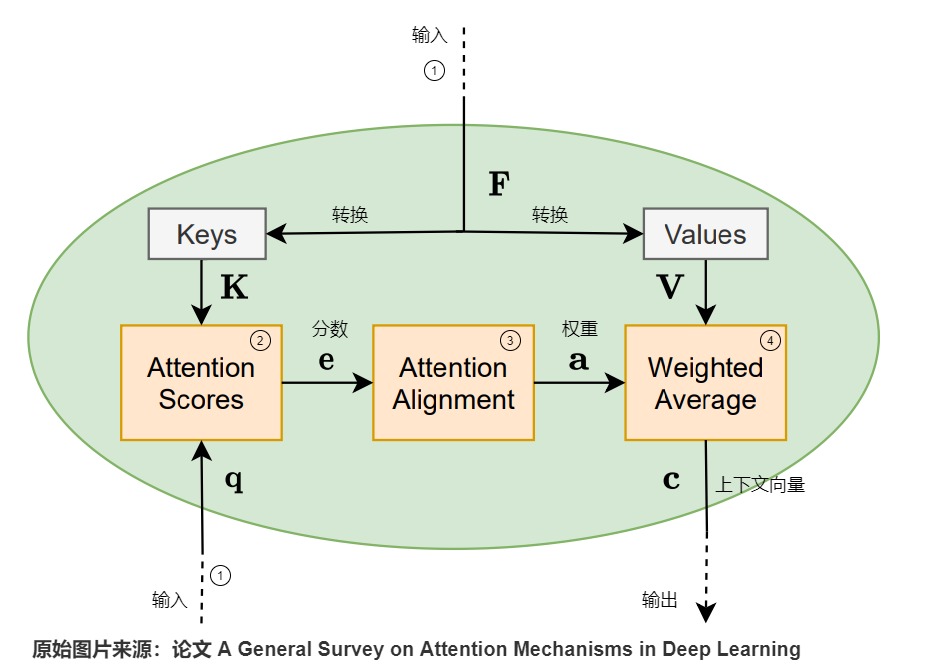
上图注意力模型中,有两个输入:q(正在处理的序列)和F(被关注的序列),F又分别转换为K和V,这三个变量综合起来使用就可以满足我们的需求。
从词典的角度来看也许可以促进理解。query是你要找的内容,key是字典的索引(字典里面有什么样的信息),value是对应的信息。
我们用淘宝搜索来类比,可以帮助我们对这些矩阵有更好的理解。假如我们在淘宝上进搜索”李宁鞋“。
- query是你在搜索栏输入的查询内容。
- key是在页面上返回的商品描述、标题,其实就是淘宝商品数据库中与候选商品相关的关键字。
- value是李宁鞋商品本身。因为一旦依据搜索词(query)搜到了匹配的商品描述、标题(key),我们就希望具体看看商品内容。
通过使用这些 QKV 值,模型可以计算注意力分数,从而确定每个token在生成预测时应从其它token那里获得多少关注。
注意力机制的计算总体可以分为两步:
- 在所有输入信息上计算注意力分布。编码器不只是传递最后一个隐藏状态,而是传入所有的隐藏状态到解码器。
- 根据注意力分布来计算输入信息的加权平均。需要注意,这是一种数据依赖的加权平均,是一种灵活、高效的全局池化操作。