02-Transformer架构解读
2.1 整体结构
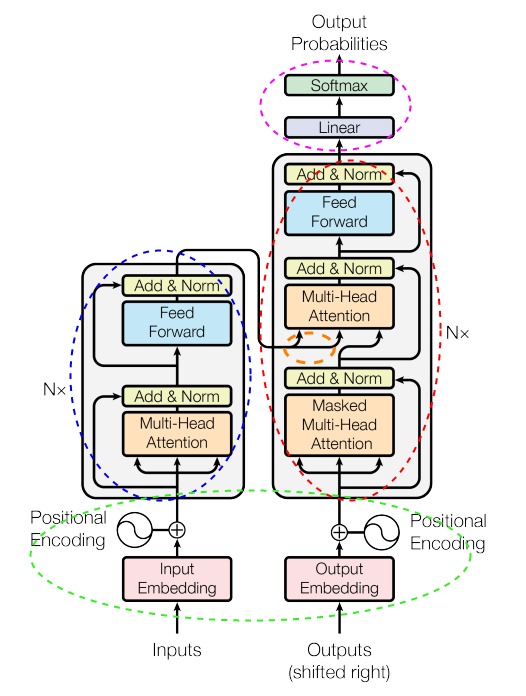
从网络结构来分析,Transformer 包括了四个主体模块。
- 输入模块,对应下图的绿色圈。
- 编码器(Encoder),对应下图的蓝色圈。
- 解码器(Decoder),对应下图的红色圈。编码器和解码器都有自己的输入和输出,编码器的输出会作为解码器输入的一部分(位于解码器的中间的橙色圈)。
- 输出模块,对应下图的紫色圈。
确切的说,蓝色圈是编码器层(Encoder layer),红色圈是解码器层(Decoder layer)。图中的 N×代表把若干具有相同结构的层堆叠起来,这种将同一结构重复多次的分层机制就是栈。为了避免混淆,我们后续把单个层称为编码器层或解码器层,把堆叠的结果称为编码器或解码器。在Transformer论文中,Transformer使用了6层堆叠来进行学习。
2.2 Attention结构
在Transformer中有三种注意力结构:全局自注意力,掩码自注意力和交叉注意力,具体如下图所示。
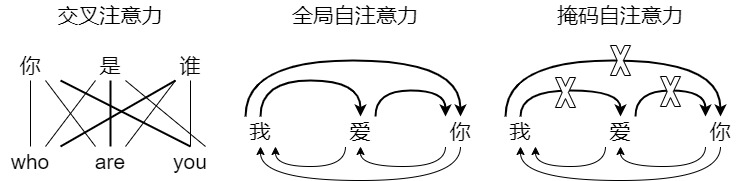

论文解读三个Attention:
Transformer 模型以三种不同的方式使用多头注意力机制:
- 在“编码器 - 解码器注意力”层中,quary来自前一个解码器层,而记忆键和值来自编码器的输出。这使得解码器中的每个位置都能关注输入序列中的所有位置。这模仿了诸如[38, 2, 9]等序列到序列模型中典型的编码器 - 解码器注意力机制。
- 编码器包含自注意力层。在自注意力层中,所有的键、值和查询都来自同一个地方,在这种情况下,来自编码器前一层的输出。编码器中的每个位置都可以关注到编码器前一层中的所有位置。
- 同样,解码器中的自注意力层允许解码器中的每个位置关注到解码器中该位置之前的所有位置。我们需要防止解码器中的左向信息流以保持自回归属性。我们在缩放点积注意力内部通过掩码(设置为 -inf)来实现这一点,掩码掉 softmax 输入中对应于非法连接的所有值。

1. 全局自注意力层
全局自注意力层(Global self attention layer)位于编码器中,它负责处理整个输入序列。在全局自注意力机制中,序列中的每个元素都可以直接访问序列中的其它元素,从而与序列中的其他元素建立动态的关联,这样可以使模型更好地捕捉序列中的重要信息。自注意力的意思就是关注于序列内部关系的注意力机制,那么是如何实现让模型关注序列内部之间的关系呢?自注意力将query、key、value设置成相同的东西,都是输入的序列,就是让注意力机制在序列的本身中寻找关系,注意到不同部分之间的相关性。
对于全局自注意力来说,Q、K、V有如下可能:
- Q、K、V都是输入序列。
- Q、K、V都来自编码器中前一层的输出。编码器中的每个位置都可以关注编码器前一层输出的所有位置。
再细化来说,Q是序列中当前位置的词向量,K和V是序列中的所有位置的词向量。
我们用淘宝搜索来类比,可以帮助我们对这些矩阵有更好的理解。假如我们在淘宝上进搜索”李宁鞋“。
- query是你在搜索栏输入的查询内容。
- key是在页面上返回的商品描述、标题,其实就是淘宝商品数据库中与候选商品相关的关键字。
- value是李宁鞋商品本身。因为一旦依据搜索词(query)搜到了匹配的商品描述、标题(key),我们就希望具体看看商品内容。
通过使用这些 QKV 值,模型可以计算注意力分数,从而确定每个token在生成预测时应从其它token那里获得多少关注。
2. 掩码自注意力
掩码自注意力层或者说因果自注意力层(Causal attention layer)可以在解码阶段捕获当前词与已经解码的词之间的关联。它是对解码器的输入序列执行类似全局自注意力层的工作,但是又有不同之处。
Transformer是自回归模型,它逐个生成文本,然后将当前输出文本附加到之前输入上变成新的输入,后续的输出依赖于前面的输出词,具备因果关系。这种串行操作会极大影响训练模型的时间。为了并行提速,人们引入了掩码,这样在计算注意力时,通过掩码可以确保后面的词不会参与前面词的计算。
对于掩码自注意力来说,Q、K、V有如下可能:
- Q、K、V都是解码器的输入序列。
- Q、K、V都来自解码器中前一层的输出。解码器中的每个位置都可以关注解码器前一层的所有位置。
再细化来说,Q是序列中当前位置的词向量,K和V是序列中的所有位置的词向量。
3. 交叉注意力层
交叉注意力层(Cross attention layer)其实就是传统的注意力机制。交叉注意力层位于解码器中,但是其连接了编码器和解码器,这样可以刻画输入序列和输出序列之间的全局依赖关系,完成输入和输出序列之间的对齐。因此它需要将目标序列作为Q,将上下文序列作为K和V。
对于交叉注意力来说,Q、K、V来自如下:
- Q来自前一个解码器层,是因果注意力层的输出向量。
- K和V来自编码器输出的注意力向量。
这使得解码器中的每个位置都能关注输入序列中的所有位置。另外,编码器并非只传递最后一步的隐状态,而是把所有时刻(对应每个位置)产生的所有隐状态都传给解码器,这就解决了中间语义编码上下文的长度是固定的问题。
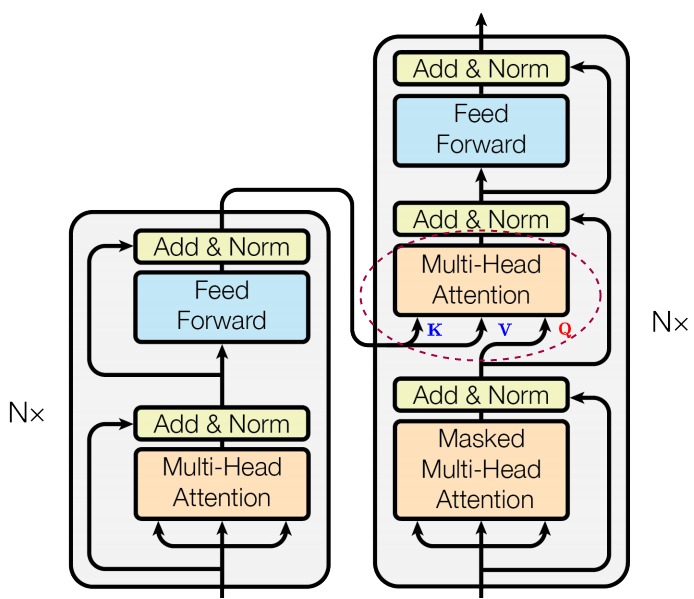
2.3 FFN层
在多个自注意力头捕获输入token之间的不同关系后,拼接的输出将通过FFN(feed-forward network)层进行处理,以增强模型的表示能力。下图展示了如何使用 FFN层将自注意力表示投影到更高的维度,以增强模型的表示能力。
FFN层由两个线性变换组成,线性变换 中间有一个激活函数。第一个线性变换将输入的维度从512 增加到四倍2048。第二个线性变换将维度降回到 的原始大小512,以确保后续层接收到维度一致的输入。
与自注意力机制在序列中彼此交流不同,FFN对序列中每个元素都独立计算,因此不会进行元素间的信息交换(元素间的互动完全靠自注意力)。这样有助于在注意力层进行元素间的信息交换之后,让每个元素消化整合自己的信息,为下一层再次通过自注意力交换信息做好准备。
2.4 执行流程
我们再来结合模型结构图来简述推理阶段的计算流程,具体如下图所示。
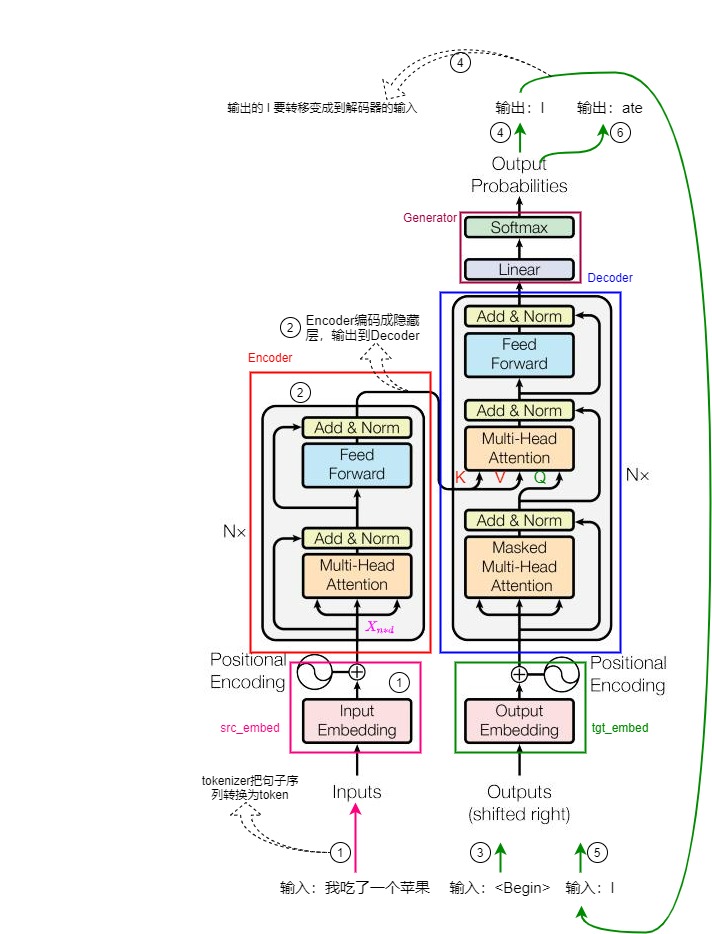
假设我们进行机器翻译工作,把中文”我吃了一个苹果“翻译成英文”I ate an apple“,在假设模型只有一层,执行步骤如下:
- 处理输入。用户输入自然语言句子”我吃了一个苹果“;tokenizer先把序列转换成token序列;然后Input Embedding层对每个token进行embedding编码,再加入Positional Encoding(位置编码),最终形成带有位置信息的embedding编码矩阵。编码矩阵用 Xn∗dXn∗d 表示, n 是句子中单词个数,d 是表示向量的维度(论文中 d=512)。注:原论文图上的输入是token,本篇为了更好的说明,把输入设置为自然语言句子。
- 编码器进行编码。编码矩阵首先进入MHA(Multi-Head Attention,多头注意力)模块,在这里每个token会依据一定权重把自己的信息和其它token的信息进行交换融合;融合结果会进入FFN(Feed Forward Network)模块做进一步处理,最终得到整个句子的数学表示,句子中每个字都会带上其它字的信息。整个句子的数学表示就是Encoder的输出。
- 通过输入翻译开始符来启动解码器。
- 解码器进行解码。解码器首先进入Masked Multi-Head Attention模块,在这里解码器的输入序列会进行内部信息交换;然后在Multi-Head Attention模块中,解码器把自己的输入序列和编码器的输出进行融合转换,最终输出一个概率分布,表示词表中每个单词作为下一个输出单词的概率;最终依据某种策略输出一个最可能的单词。这里会预测出第一个单词”I“。
- 把预测出的第一个单词”I“和一起作为解码器的输入,进行再次解码。
- 解码器预测出第二个单词”ate“。
针对本例,解码器的每一步输入和输出具体如下表所示。

3. 补充
论文"Attention is not all you need"指出如果没有skip connection(residual connection-残差链接)和MLP,自注意力网络的输出会朝着一个rank-1的矩阵收缩。即,skip connection和MLP可以很好地阻止自注意力网络的这种”秩坍塌(秩坍塌)退化“。这揭示了skip connection,MLP对self-attention的不可或缺的作用
在Transformer架构图中,Inputs和Outputs的上面分别有一个Embedding模块,每个模块都是由两个子模块组合而成。
- Inputs相关的embedding模块包括Input Embedding和Positional Encoding。
- Input Embedding负责把token编码。
- Positional Encoding负责给token加入位置信息。实际操作中,Transformer会一次性接收整个输入句子的嵌入矩阵。这样做的好处是可以并行操作,但是劣势是缺少位置信息,比如模型无法区分“我爱你”和“爱你我” 。Positional Encoding就负责给每个词增加位置信息。
- Outputs相关的embedding模块包括Output Embedding + Positional Encoding:与上面类似,不再赘述。